So on Thursday December 14th what I am calling the Brawl to Settle Absofuckinglutely Nothing occurred between myself and Mike Israetel. I guess this means that Mike and I were each other’s Valentine’s day date. Take that how you will.
Since the discussion was time limited (it still went 90 minutes), there were some things in the middle that weren’t addressed. More than that, it would have just lengthened it to go in circles. So I’m using this platform to talk about them. Mike can do the same.
First, one very important comment, in much of this I have been spelling Mike’s last name wrong, as Isratel. It wasn’t deliberate, just a mistake. It’s Israetel and I will make efforts in the future to get it right. I certainly meant to mention this in the debate and hope I did. Already the memories fade. But I wanted to make that correction.
Note: this piece is too fucking long, I was writing quickly, Im’ sure there are typos and fuck it, I want this out of my head.
Table of Contents
The Debate
Steve Hall ‘oversaw’ the debate inasmuch as he basically just let us go. He gave a brief intro, turned it over to us, did the extro. I think he made one comment in the middle but that was it.
In terms of what it was, there was no problem with any of it. It was very civil and I think Mike cursed more than me. I suspect many thought I would fly off the rails but, well…the Internet is not real folks. Never forget that.
Nobody “told each other to their face” what they thought, by the way, that’s just a bunch of Internet posturing (though I’m fairly sure I never said that to begin with). And we both got an equal amount of time to give our arguments. I fought against a very bad habit I have of interrupting people in the middle of a sentence to disagree with something and think I did a pretty good job. Mike never interrupted me. I’d speak, he’d respond, I’d respond, we go in circles and then move on when we both got tired of repeating ourselves.
But I would consider it as fair as fair can be. Nobody was getting cut off or shut down or not given the opportunity to speak.
The debate was divided into two parts. I went first, addressing some of the problems I have with Brad’s paper. Mike went next for the volume debate. From what I can tell, both bits were about 45 minutes of the total run time. Like I said very fair and balanced.
I was very prepared for this. I had 22 pages of notes, 13 on my topic and 9 for what I thought he might bring up. In preparation I read as much of his extant material as I could. Yeah, a little over the top but I don’t like surprises and always plan for contingencies. It was overkill, we didn’t have time to address most of it and I dropped a lot of my babble out on my half since it was summarized more quickly.
I even got a crash course in statistics from a good friend, it’s something I’ve needed to bone up on anyhow (Hi Tal). Perhaps the high point for me was being able to get through my explanation of both P-values and BF10 factors without fucking it up completely. Anybody who can get me to understand statistics even conceptually is a damn good teacher.
Mike was also prepared, I could tell he was looking at his screen and he pulled stuff up on his phone. I’d have expected nothing less though I don’t know if he was quite as psycho as I was about it. Few are but I’m the man who writes books supposedly for popular consumption with 600+ references. I’m a touch obsessive and more than a touch crazy although I suspect my obsessiveness is part of why I’m a little bit crazy (how can you not be when you read 9 different review papers on one topic multiple times each). Anyhow.
One thing: I told Mike twice that he’d make a good politician. He said he didn’t understand what I meant. I’ll explain at the end.
I want to look at this debate in reverse order for efficiency.
The Volume Debate
In short, and you can listen to it yourselves, there was basically no debate. Mike and I agreed on about 90-95% of his points and the points we disagreed on were not only fairly minor but context dependent. The major one being the difference in the general trainee and the advanced athlete in terms of whether MRV should be approached or used along with potential pros and cons. Like I said, it was a non-debate.
I did my best to answer any questions he had to me directly, I also asked for clarification as needed to make sure I was answering the actual question. You can listen for yourself and decide if I was direct in my answers since I certainly tried to be. But like I said and predicted all along, he has more disagreement about this with others in the field than he has with me.
The Schoenfeld Debate
In leading into my part, Steve gave a brief precis. In short, Brad took 3 groups of men, put them on the same full body workout of all compounds (plus leg extension for quads) and had them do 1,3 or 5 sets per exercises. This yielded set counts of 6,18 and 30 for upper body and 9, 27, and 45 for lower body.
Note that they only measured growth in biceps, triceps, rectus femoris and quadriceps and, as I’ve stated elsewhere, I think counting compound sets as 1:1 for ancillary muscles is flawed. A bench press hits triceps but 1 set of bench is not the equivalent of 1 set for triceps. I estimate it as 0.5 set and, for the record, Mike does too, at least according to this article. Since it can clearly be done, I don’t understand why studies fixate on these muscles. Pecs, shoulders, glutes and I suspect others can be measured. So do it.
The study lasted 8 weeks, weights were increased as they went and I’d bring up another point. The workout was structured as #setsX12-15 RM (rep max) on a 90 second rest. Let’s reality check this. Ok, have any of you squatted to failure? Probably not. How many of you could do 5 sets of 15 to failure on 90 seconds. I’d say none unless you dropped the weight to inconsequential loads. Most men need a few minutes to lie down after a true set of 15 to failure. 90 seconds is absurd. I think this is the definition of junk volume.
Changes in muscle growth was made by Ultrasound, a method that is commonly used but which has a subjective component and isn’t ideal but since many studies use that this isn’t a dismissal. It’s what they did and as you’ll see, I focused only on what was done on the study because that is my main issue.
Their results purportedly claimed that the higher volumes led to proportionally more growth as indicated in their (in my opinion strongly worded) conclusion:
“Alternatively, we show how that increases in muscle hypertrophy follow a dose-response relationship, with increasingly greater gains achieved with higher training volumes. Thus, those seeking to maximize muscular growth need to allot a greater amount of weekly time to achieve this goal. “
If you’re wondering about the alternatively, it’s because study also found, going against about the entire body of literature that strength gains were identical between groups (this was Steve’s one commentary). Sure. Since I am only focused on the hypertrophy I won’t come back to that since it has never been part of this for me outside of being laughably unbelievable (and I think supportive of no real difference in growth since a bigger muscle is generally a stronger muscle).
So I had drawn up as many as 5 points although I only focused on 3.
The Blinding Issue
First let me briefly explain blinding. Essentially it’s a way to limit bias by preventing someone from knowing who is doing what. So in a drug trial, you give two groups either the drug or a placebo but you don’t tell them which they got so they have no expectations. That’s a single-blind. You can blind the researchers as well. So they don’t know which subject got what which might bias what they see. That’s a double blind study.
You can go further. In exercise studies it may be possible to blind the subjects or people supervising the exercise although that’s tougher. Clearly you know how many sets you’re doing, so do the people supervising the workout so this is more challenging. At the very least, have exercise specialists who aren’t involved in the study per se do this if you can.
You could blind the statisticians (just give them the data and tell them to analyze it without telling them anything else). There is a push to blind peer review so that the reviewers don’t know who wrote the study. This way they don’t give someone less rigorous attention or more for some reason such as liking the researcher, disliking someone for previous work. This would be a good thing but it’s not un common use.
Here’s an easy example, from the symphony to help you understand why blinding is important. Back in the day when musicians applied for positions, the conductor, usually male, would sit and listen to the musician play in front of them. And at someone noticed that less women were getting jobs. So they put a curtain in front of the musicians so that the conductor didn’t know if the musician was female or male, he just heard the music. And suddenly females started getting more jobs. Because now only the performance was being measured and things such as sex/gender, ethnicity or attractiveness weren’t a factor anymore. We all have bias, I do, you do, researchers do, no human is without it.
Blinding reduces the risk of bias. I didn’t say eliminates. But the more you can do it, the better.
As I said above, Ultrasound was used to measure muscle thickness changes and this is common. Other methods such as MRI, DEXA and even biopsy are also used (and I’d note that the study Mike was involved in used DEXA, Ultrasound and biopsy of the quads making it MUCH more rigorous in this regard since you can see if trends in support of growth go in the same or different directions. His study made some intriguing observations due to this). And it has a subjective component due to how it works.
And in Brad’s study, it was stated:
“The lead researcher, a trained ultrasound technician, performed all testing using a B-mode ultrasound imaging unit (ECO3, Chison Medical Imaging, Ltd, Jiang Su Province, China). “
That is, Brad did the measurements himself, and he knew who was in which training group.
Now, in science, there are various tools to analyze studies for problems. In fact there are about 18 or so.
Source: Page MJ et. al. Tools for assessing risk of reporting biases in studies and syntheses of studies: a systematic review. British Medical Journal Open 2018.
One of the most commonly used is the Cochrane Risk of Bias Tool and I’ll focus on that since Cochrane reviews are right at the top of the heap.
Source: Jorgensen L et. al. Evaluation of the Cochrane tool for assessing risk of bias in randomized clinical trials: overview of published comments and analysis of user practice in Cochrane and non-Cochrane reviews. Syst Rev 2016.
In Appendix F, page F-2 it lists blinding of outcome assessments as a detection bias. And states that a high risk of bias occurs when
“Detection bias due to knowledge of the allocated interventions by outcome assessors
Outcome assessors are the guys doing the measurements. In this case it was Brad. And he knew who was in which group. And according to scientific standards this raises a high risk of bias. That is not the same as saying that there IS bias. Just that a lack of blinding raises that risk. In contrast, an effectively blinded study means a low risk of bias. Again, it doesn’t mean it’s impossible, it reduces the risk. Blinding is simply good scientific practice to reduce the risk of bias wherever possible.
Over to Mike
So I turned it over to Mike. And while I will probably forget one of two, some of his arguments follow and all of them are more excuses and deflections than answers.
First Mike argued that lots of studies aren’t blinded. Yeah, and? This is akin to a guy on trial for drunk driving saying “But lots of people drive drunk” Right, and they aren’t on trial. That other studies are equally sloppy doesn’t make it OK for any given study to be sloppy.
Similarly, Mike argued that sports science isn’t as rigorous as say medical research. That Cochrane doesn’t really apply since it’s for medical trials. Well, it’s true that a lot of sport science is poor. But just as the above, so what. That just means those other studies are bad too. It’s not a defense for any given study to be poorly done. And by that logic, why not throw out sports science completely? If your fall back is “Most of this research is awful” let’s go back to doing what Arnold did and just rely on anecdote. If you’re going to do science, adhere to the method and the rules. Don’t’ excuse it because others do it poorly or “Because it’s hard to get right”.
Mike then argued (and I’ll get these out of order) that I’ve never paid attention in articles to blinding before. Or that dismissing studies that weren’t blinded would eliminate most of the content on my website. Perhaps true (and I’ll come back to point one) but equally irrelevant.
They rarely talk about blinding in meta-analyses (Brad has never done it in his so far as I can tell) and few others on the Internet do either. Irrespective of that it’s irrelevant. My work is not on trial. My actions are not on trial. The ONLY issue is the blinding of Brad’s study since that is what we are discussing. Another deflection. .
But there’s no arguing with that kind of defense. What other papers have done is irrelevant. That sports science is often weakly done is irrelevant. Saying that you shouldn’t hold sports science to the same standard as medical research…well, why the fuck do it at all then? Just let it be a free for all. Guidelines exist fora reason and sloppy science is sloppy science regardless of the field (most social science and psychology research is a fucking disaster).
Hilarity
In that vein, here’s a bit of hilarity that I didn’t bring up. In a recent paper/opinion piece, a ton of folks including Andrew Vigotsky, Greg Knuckols, Bret Contreras and Brad Schoenfeld (with many others) wrote a piece calling for increased transparency in sports science. Basically a call to improve the merit of the field. Their focus is on several problems (in all research) and talks about pre-registering trials and the idea of a Registered Report.
Basically sending in the study design for peer-review before doing it so that any problems can be identified and fixed. And with the promise that the paper will get published so long as it does what it says. Brad has never pre-reigstered a paper of his and I’ll be shocked if he does the Registered Reports. I guess Brad only wants higher scientific standards for everyone else.
Other Papers Seem to Be Able to Blind
Adding to this, I decided to look at some other papers to see what they had done. Now the paper Mike was involved with by Haun did not mention having the tech blinded. It does appear to have had someone not involved with the study (based on the initials) do it but I can’t say more than that. However, in many of their other studies, the Ultrasound tech was blinded.
DeSouza. Effects of Arachidonic Acid Supplementation on Acute Anabolic Signaling and Chronic Functional Performance and Body Composition Adaptations PLoS One
“The same investigator performed ultrasound assessments pre-to-post experimental period and was blinded to the treatment groups.”
Wilson JM The Effects of Ketogenic Dieting on Body Composition, Strength, Power, and Hormonal Profiles in Resistance Training Males. J Str Cond Res
“The same investigator performed all ultrasound assessments and was blinded to the treatment groups.”
Haun et. al. Soy protein supplementation is not androgenic or estrogenic in college-aged men when combined with resistance exercise training. Sci Rep
“Between these two time points, subjects consumed either PLA, SPC, or WPC twice per day, while both subjects and researchers were blinded to subject grouping.”
Wilson JM et. al. Effects of oral adenosine-5′-triphosphate supplementation on athletic performance, skeletal muscle hypertrophy and recovery in resistance-trained men. Nutr Metab
“ultrasonography-determined muscle thickness of the vastus lateralis (VL) and vastus intermedius (VI) muscles. The mean of three measurements by the same blinded investigator were taken at 50% of femur length over the mid-belly of the muscle with the subjects lying in a supine position.”
So that’s sort of funny. The guy running the lab that the study Mike was involved with seems to be able to get it right as often as not. I’ve said from the get go, that that paper was methodologically heads and shoulders above Brad’s. I might question Mike’s agenda for defending slop (which I did in my initial video but didn’t do in the debate) from Brad when his own guy can do it right but then I’m as bad as him.
Other labs get it done too.
Jessee MB et. al. Muscle Adaptations to High-Load Training and Very Low-Load Training With and Without Blood Flow Restriction Front Physiol. 2018; 9: 1448.
“All measurements and analyses of muscle thickness were taken by the same investigator throughout the study. To limit any bias, the investigator was blinded to each condition during image analysis, which was done only after all testing was completed.”
Dankel SJ et al Post exercise blood flow restriction attenuates muscle hypertrophy. Eur J Appl Physiol
” All images were printed and analyzed by the same investigator who was blinded to the condition”
It’s almost as if you can actually do proper science when you try. Unless you’re Brad.
Brad Schoenfeld Can’t Blind a Single Paper
For contrast, I pulled all of the studies with Brad’s name on them on muscle growth. I found 17 of which he was lead researchers (so presumably the work was out of his lab) on 12. Two mentioned explicitly being UNBLINDED and the rest didn’t mention it which I will assume means they were unblinded (it is standard to STATE if something was blinded and I take no mention of it to mean that it wasn’t). Out of others, 3 where he wasn’t lead researcher blinded the techs and the others did not (and the numbers may be slightly off). Here’s the chart.
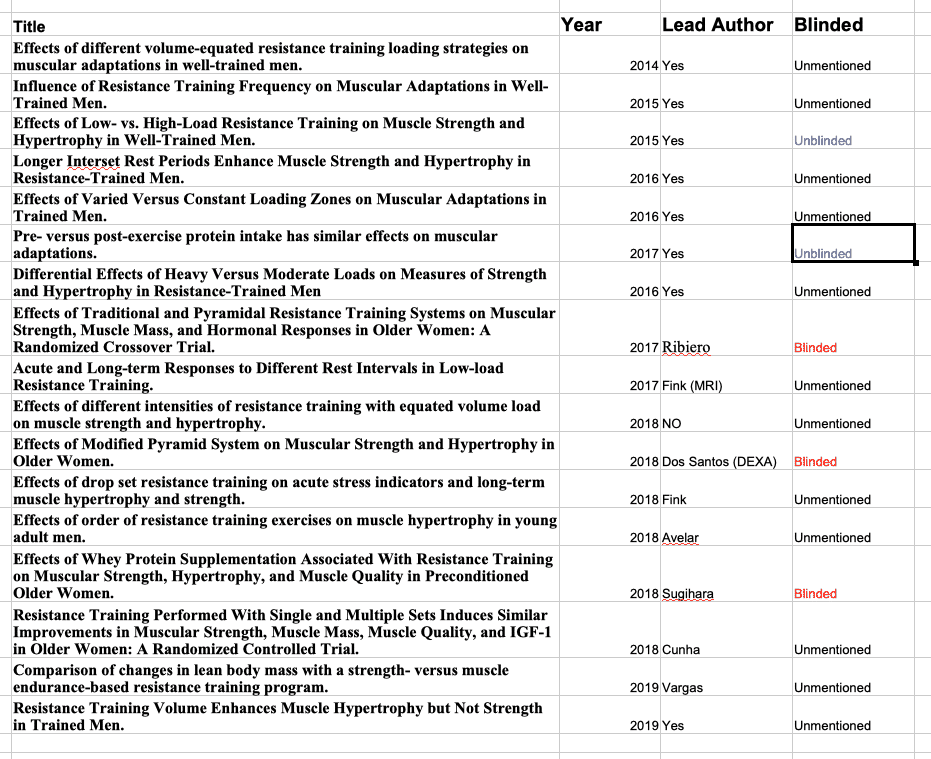
Mike’s last defense that I recall was to say “Ok, should it have been done, yes? In hindsight was it weak? Yes. If they replicated it, they should blind it?” This is the “We made mistakes in the past defense.” Hey, here’s a neat idea, why not get it right the first time? This is just pitiful.
So basically it was all a lot of political type excuses. Others do sloppy science, you report on sloppy science, the field is weak, guidelines don’t hold for our science, Brad should have done it and if he replicates he really should. These are simply excuses for bad science.
Brad Isn’t Biased?
Another one of his defenses was that Brad can’t be biased (Brad uses this himself) because this paper’s results contradicted his previous work. Well it didn’t in the first place because his conclusion was NOT supported but that’s a non-reason in the second place. Why fucking have standards to begin with if you’re going to say you don’t need them because you’re trustworthy?
Either use them or don’t use them but don’t make up bullshit for why you’re the only trustworthy science in the group who shouldn’t have to follow them. Reducing bias to as great a degree as possible is part of proper scientific method and the “You can trust him” is not valid. Blinding exists for a reason and GOOD scientists attempt to do it as much as possible.
Brad has never blinded a single study out of his lab. Not one. It’s not as if Brad is some virgin researcher who doesn’t know what he’s doing the first time out of the gate. This is a man who I am told teaches a class in scientific methodology. Perhaps he should take a refresher course.
He knows what good science entails, he sure as hell gets up other people’s asses when they publish a paper he doesn’t like. But apparently he’s incapable of doing it properly himself. If Brad is going to crow about being a man “in search of the truth”, he should do everything within his power to do good science. Either he doesn’t know how or is too lazy or too incompetent.
Tl;dr: Mike made excuses for Brad’s unblinding to say it was ok because other studies are bad, I’ve reported on unblinded studies and a whole bunch of other irrelevancies. It was an excuse for Brad’s continual sloppy science based on smoke blowing not an acknowledgement that it was poor science (beyond yes, it could have been done better in hindsight)
The thing is this: if you do it right the first time, you don’t have to make bullshit excuses after the fact. So why not aim for a higher standard than “Well other science is poor?” Sure, let’s make it all better.
The Statistics
Ok, so this was a major place I needed help prior to the “debate” and I had a friend give me a crash course. Apparently I got it enough right. Studies do statistical analysis to see if there findings are, well not ‘true’ exactly but true enough, sort of.
Basically you have a hypothesis you’re going to test “Does this change have this effect” and you have a null hypothesis “This thing doesn’t have this effect” and it’s way more complicated than this. And there are a billion statistical tools to examine this to see if your results can be deemed ‘real’ (sometimes shit happens by accident). None of that is important.
What is important is that Brad’s paper used two statistical methods. The first is called Frequentist which generates what is call the P (or probability) value. I’ll just quote the online definition for ease:
A small p–value (typically ≤ 0.05) indicates strong evidence against the null hypothesis, so you reject the null hypothesis.
Again, you don’t really need to understand this in detail. Just understand that a P value of less than 0.05 is usually considered significant. Now, I noted in my introduction that there is HUGE debate over the validity of P values. It’s bunch of complexity revolving around whether 0.05 is low enough, should there be an absolute cutoff or a continuum and other stuff.
It doesn’t matter here. What matters is that Brad and James Krieger (who did the stats) picked a P cutoff of 0.05 or lower which means THEY HAVE TO LIVE AND DIE BY IT. What I think doesn’t matter. What anybody else thinks doesn’t matter. They picked it, they have to accept the consequences.
And simply, the P value analysis didn’t support the conclusion. For one of the 4 muscles, the group analysis P was above 0.05 which means that there was no statistical difference in groups. This doesn’t mean they grew the same, it means there wasn’t enough of a difference to reject the null. But they didn’t even compare groups here.
For the other 3 muscle’s group analysis, P was below 0.05. So there was a group difference but they didn’t know what it was. Since there were three groups so now you do pair-wise comparisons: low to moderate, low to high, moderate to high. And without getting into the weeds on this, while there was support for the higher volume groups beating out the lower, the subscript on the moderate and high volume sets was the same. By this analysis, THERE WAS NO STATISTICALLY SIGNIFICANT DIFFERENCE between the high and moderate volumes. It’s in Figure 1 plain as day.
Boom, done. They picked P < 0.05, they didn’t meet it for high vs. moderate. That equals NO SUPPORT for their claim. If, like most studies they had only used this analysis, they would have had to conclude that there was no significant difference between groups. This isn’t debatable on any level. They chose the stat, they choose the cutoff, their data didn’t meet it. QED
Then I turned it over to Mike.
Over to Mike
First he repeated what I had said about the P value debate. True but irrelevant which is why I brought it up ahead of time. Brad and James picked it, Brad and James have to accept it or not. Then it was basically the same litany of excuses as above. Well a lot of studies have weak statistics, some of the papers on your website have weak statistics, there are a lot of different methods, the field is weak.
You get the idea. Perhaps all true. But all still irrelevant. Brad and James picked their value, they have to live by it and what happens in the rest of sport science doesn’t make a single fuck’s worth of difference to the actual study being discussed. Saying “All studies have limitations” is trite but meaningless.
So then we went to the second analysis which is Bayesian. Again, the details don’t matter but essentially this lets you assign a probability that one hypothesis is more likely to be true (or supported by the data than the other). This is done by generating what are called Bayes Factors (BF) although there’s much more to Bayesian stats.
Again, you don’t need to understand the specifics, just what it means. Because BF10 (pronounced BF one zero in contrast to the BF zero one or BF01) values have accepted cutoffs and descriptions. The ones used by Raferty, the paper cited by Brad and James (hence the one that they must adhere to) uses these for BF10:
<1 No support
1-3 weak support
3-20 positive support
20-150 strong support
150+ very strong support
So higher values mean more support. Other sources use other descriptors and slightly different cutoffs, I’ll come back to this. The only values you need to remember are between zero and three.
For one muscle, the triceps, the BF10 was less than 1 so there was no group difference. Again, this doesn’t mean all groups grew the same, just that there was NO support for a difference between any group. For the other three, the BF10 was sufficient do require a pair wise analysis.
Again, I only care about moderate to high since I won’t argue that both grew better than the low volume group. For biceps, the BF10 for 5 vs. 3 was 0.6. No support. For rectus femoris it achieved a whopping 1.43 and for quads 2.25. So weak support in both cases. For two of the four muscles measured. So it was a tie, 2 muscle with NO SUPPORT and 2 with WEAK support (the word “weak” was even used in the results section)
I said other sources refer to the numbers differently descriptively. Jefries, the father of Bayesian stats says BF10 of 1-3 are “not worth more than a bare mention.” Wagenmakers calls it “anecdotal.” Basically, less than 3 is pretty damn meaningless unless your name is James Krieger.
Note: In his response to Brian Bucher on Redditt, James asserted that “a Bf10 less than is not considered weak according to all classifications” Ok, first and foremost this requires James to provide a reference that shows that. Which he did not. Second and secondmost, it doesn’t matter. They used Raferty IN THEIR PAPER. They have to live by what THE PAPER THEY PICKED says. If he has an actual reference that says 3 is worth a shit, they should have referenced that IN THEIR PAPER. They did not. Hence Raferty’s descriptions stand. To my knowledge, James has still not provided this asserted reference. Because it doesn’t exist outside of the land of unicorns and gurus.
Edit: As of May 2020, despite several requests, James has not sent me the supposed reference he claims exists. Bottom line: it was a flat out goddamn lie.
Ok, let’s sum up. By P value, there was NO support for a difference between 3- and 5- sets for any muscle. By Bayesian values, there was NO support for a difference in biceps and triceps and weak/anecdotal/not worth more than a bare mention support for 5- being superior to 3- for rectus femoris and vastus lateralis.
I am told Greg Knuckols said that James and Brad “oversold the statistics”. I think that’s being generous as hell. These stats didn’t mean shit and even if you think weak support means something it was for 2 of 4 muscles. So literally out of 8 analyses (4 P value 4 Bayesian and yes I know you can’t really count them like this) 2 of 8 were weak support. C’mon.
Because this was the conclusion
“Alternatively, we show how that increases in muscle hypertrophy follow a dose-response relationship, with increasingly greater gains achieved with higher training volumes. Thus, those seeking to maximize muscular growth need to allot a greater amount of weekly time to achieve this goal. “
The stats don’t support this conclusion. They did NOT show that muscle hypertrophy follows a dose-response relationship with increasingly greater gains achieved with higher training volumes except for weak support in 2 muscles out of 4. They didn’t use the words trend, suggest or anything else. They said “we showed”. Their stats showed no such thing.
So I turned it over to Mike.
First it was the same litany about statistics being limited, other studies being limited, etc. I won’t keep writing that up. I told him it didn’t matter, they choose those methods, they live and die by them. Other papers don’t matter. Debate over P value doesn’t matter. They picked it, they have to accept it. Period.
He said that in later description of the study they DID temper their words from the orginal conclusion. Well I didn’t see that because I was blocked from the get go. Mike pointed out that I block people all the time. And?
I call this the Bret Kavanaugh defense. When he was asked if he had ever been blackout drunk he asked the questioner “Have you?” It’s the worst kind of smokescreen. Also, I don’t block people for asking me to answer criticism of my work by and large (and most of the people I blocked were years ago for reasons related more to my bipolar when I would block people for absolutely fucking nothing). But , Mike says,I insulted Brad (who demands answers to his questions all the). Well Brad needs to butch the fuck up and get over words on a screen. My actions aren’t relevant here anyhow.
And what they wrote later doesn’t matter. If it wasn’t in the paper it is irrelevant to the discussion. Any data pulled out later (like James did with that bullshit leg extension load volume doesn’t count). I don’t care if someone does an Effect Size analysis after the fact. If it wasn’t in the paper that was published, it’s not relevant to the discussion. They choose P value and BF10 in the paper, those stats didn’t support their strongly worded conclusion. QED.
It didn’t keep Brad from crowing about it initially and James saying on Youtbe that “we have new data that will BLOW CURRENT TOP END VOLUME RECOMMENDATIONS OUT OF THE WATER.” They presented it strongly in the paper, on social media and even if they backed off later on, it doesn’t matter. They didn’t temper it in the paper or with their initial announcement.
These were not tempered conclusions. They were strong conclusions unsupported by the statistical methods the researchers choose to use and had to accept.
Not Strongly Worded?
And then Mike told me he didn’t think the conclusion was strongly worded. Wait, what? He said that since it didn’t explicitly say “Do 30-45 sets per week” it wasn’t a strong conclusion. Oh bullshit. It said we show (they didn’t) a dose-response relationship (that didn’t exist) and, holy crap you can’t argue with smoke. And we went around in circles for a while until I gave up.
Draw your own fucking conclusion about whether or not this is strongly worded:
“Alternatively, we show how that increases in muscle hypertrophy follow a dose-response relationship, with increasingly greater gains achieved with higher training volumes. Thus, those seeking to maximize muscular growth need to allot a greater amount of weekly time to achieve this goal. “
It say more volume equals more growth. Not tended towards, not suggested, it didn’t even differentiate the fact that it was ONLY weak support in TWO muscles. It was weak ass support for 2 of 4 muscles with one statistical method (and zero support with the other) which shows nothing.
That it didn’t specify a set count is irrelevant. It says flatly more volume equals more growth. That’s strongly worded as hell. I mean, shit, if I said “The less you eat the more fat you will lose:” that’s a strongly worded conclusion. That I didn’t say 400 calories or whatever doesn’t make it any less strong. But that’s what his argument amounted to.
The Accusation
About this point in the “debate”, as I was getting exhausted listening to Mike run in circles, he made an accusation I was expecting. First he was wondering why I was overvaluing this particular study and focusing my attention on it. Well, I’ll get to that. He also, and I knew this was coming accused me of being so critical of this study because it disagreed with me.
Which is actually completely wrong. I could give a fuck about the results per se to be honest. If the paper were valid if the data supported the conclusions (and the stats LITERALLY do no such thing), I’d be happy to accept it (and let’s be honest we are ALL a bit more critical about studies that disagree with us than those that don’t).
But this is also just putting me on trial again. The Kavanaugh Defense part 2. The “What’s your agenda?” argument I got thrown at me. Our president uses it all the time: he deflects answering criticism by asking the journalists why they are trying to destroy him. Defelect, ignore, attack the person asking the questions. It works but it’s horseshit.
He then asked me why I hadn’t done as great an analysis of the Barbalho study that came out last year. This was the first does response study in women, finding a shockingly low volume of training gave optimal results. Did it not also contradict me, why hadn’t I analyzed it too?
Edit, I did eventually analyze it. And it makes Brad’s paper look like the kindergarten effort that it is.
Well there are a few reasons. One it’s on women and that’s a different population group where there might be differences. I will admit that the conclusions, which I only sort of skimmed did surprise me since it goes against a lot different ideas. A lot of it was just time, I’ve had notes on my desktop about the paper and meant to delve for a while. Third, this is just another deflection.
What I have or have not done with other paper’s is irrelevant to MY ACTUAL CRITICISMS OF BRAD’S PAPER. That said, I’ve already done about 80% of my analysis, I mean in-depth with a fine toothed comb on Barbalho (I did it last night after the debate). I’ll run it next week. And well, no spoilers but Mike bit himself in the ass with by challenging me to this. It’s fun.
So what then is my issue with Brad’s paper, why am I so focused on this one paper. Well that’s point 3.
The Lie (ok, Misrepresentation)
Ok, I’ve droned on and on about this forever and this is too long so I’ll try to keep it brief. The long and the short of it: when you do a study you usually compare it to previous research to see whether other studies agree (ideal, replication is key) or disagree with you. If the latter, you might examine why to see what might explain the differences.
And what kicked this whole thing off was when Brad sent me the prepublication and I read the discussion and a paper stood out to me and I went to look at which it was and I had read it and, basically, how Brad represented the data was not only wrong but reversed the conclusion to agree with him.
The paper is Ostrowski et. al and was extremely similar to Brad’s it used similar numbers of similarly trained men with a split routine and 1,2 or 4 sets per exercise. This yielded, 3,6 and 12 sets for legs (there was only one leg day) and a similar 7, 14 and 28 sets for upper body.
Well triceps since the study only did Ultrasound on rectus femoris and triceps (the study does not mention if the tech was blinded and I will assume it’s not). Again we have the set counting issue and compound vs. isolation although this included isolation movements due to an arm day and there’s not space for this. It was 10 weeks long.
The results of Ostrowski were as follows. First there was no statistically significant difference between any groups for either muscle. Again, this doesn’t mean they grew the same, just that there was no difference. In two different places, his textbook and a paper he wrote on volume, Brad lists Ostrowski as showing no statistical difference. So in those two places at least, he represented it accurately. For the record.

Now, I’m only going to focus on triceps for reasons you’ll see although quads will come back into this. What Ostrowski found in terms of the raw data was that the groups got 1, 2 and 2 mm absolute growth and 2.3, 4.7 and 4.8% change for 7, 14 and 28 sets respectively.
Ok, so it wasn’t statistically significant, but there is a visible trend. I’m not saying we can do this, that we can ignore the stats and just look at the numbers. That’s why you do statistics. But assuming we agree that there is a trend, we see that growth doubles from 7 to 14 sets and goes no higher for 28. A plateau.
Let me digress. One of Mike’s refrains on this was that he wasn’t sure he agreed it was a plateau (I may be garbling this somewhat). Umm, ok. 2.3, 4.7, 4.8 and 1,2,2 seems to be a pretty damn visible plateau to me. But I can’t argue with smoke like that. I say it’s a plateau, he says “I don’t see it” and boom he’s “won”. It’s a great dismissal but whatever. You can decide if you agree with him or not based on those numbers.
So back to the point. In reporting the above data, Brad wrote this:
“Results showed that percent changes and ESs for muscle growth in the elbow extensors and quadriceps femoris favored the high-volume group. However, no statistically significant differences were noted between groups. When comparing the results of Ostrowski et al. (11) to the present study, there were notable similarities that lend support to the role of volume as a potent driver of hypertrophy.
Changes in triceps brachii MT in Ostrowski et al. (11) study were 2.2% for the lowest volume condition (7 sets per muscle/week) and 4.7% for the highest volume condition (28 sets per muscle/week). Similarly, our study showed changes in elbow extensor MT of 1.1% versus 5.5% for the lowest (6 sets per muscle/week) versus highest (30 sets per muscle/week) volume conditions, respectively.”
Read it closely, and notice that he only reported the lowest and highest set counts for Ostrowki (he did the same thing on legs for no real reason except, I suspect to set up the trend so he could do it here). And in doing so make it seem like the highest volumes in their group matched the highest volumes in his. See, more volume is better. Ostrowski’s results are just like ours.
First and foremost, let us not forget that the stats for triceps had a non-significant P value for any of the three groups and a non-significant BF10 value as well in Brad’s study. That it was similar is irrelevant since the values weren’t significant in either study. I mean, they were similarly insignificant I suppose. That is, meaningless in a purely statistical sense.
But that’s not my issue. By reporting it this way, by ignoring the middle group, Brad makes it sound like more was better. It wasn’t. Assuming you agree that there was a plateau in the data (1,2,2 or 2.3%, 4.7%, 4.8%) 14 grew as well as 28. And this is NOT similar to Brad’s study.
In fact it’s the opposite of Brad’s study because the moderate group was as good as the high group (and let me note again that Brad’s paper provided no support for more being better in triceps to begin with). The highest group was NO BETTER than the moderate group. And Brad is still claiming with zero statistical support for triceps that more was better. Simply:
Ostrowski actual data on triceps: More was not better
Brad (unsupported) claim for his actual data on Triceps: More was better
Brad reporting on Ostrowski: More was better
See the problem? How he reported it changes the actual conclusion from contradicting to agreeing with him.
Now we can quibble whether this is a lie or not. Except that Brad and I discussed this 2 years ago and he was very aware of the above. He said that he reanalyzed the data for his discussion so he knew what the data said. And he CHOOSE to represent it in a misleading way. Knowingly misrepresenting or misleading someone is a lie.
So I turned it over to Mike.
Over to Mike
His first defense was that he didn’t feel as if it was misrepresented. That what was written was strictly speaking true. That Ostrowski did show that 28 sets generated that response. That if Brad had said “Ostrowski had shown a dose-response relationship” it would have been a lie. This is semantic nitpicking of the worst kind and I had seen it before: James made the same weak argument in my group.
Now, it is technically literally true. But it is also misleading (and let me note that James himself finally admitted it was a misrepresentation of the data) as hell. In describing it this way, it turns a growth plateau into a more is better response and that’s not true.
If I told you I had 3 cars that cost 70k, 140k and 280k and their top speeds were 100, 200 and 200 it would be literally true to say “The 70k car goes 100mph but the 280k car goes 200 mph”. But it wouldn’t change the fact that the 140k car was just as fast and you’d be paying double for no more benefit. And I bet if I sold you that 280k car without telling you about the 140k car you’d think I’d lied to you about it. Because I would have.
And that’s not what the paper showed (again ignoring that even Brad’s paper showed no statistical difference for triceps in any group). But I guess he figured he could just go to the percentages and ignore that. Ignore the stats that say there’s no difference in both studies and just try to make them look the same by ignoring a data point you dislike.
Note: some may say that I’m doing the same by looking at the percentages. True. But I’m also not the one holding up Ostrowski as showing more is better, Brad is. When I wrote about this paper in my volume and hypertrophy series, I described as as being non-significant but showing an apparent trend where the middle group was best. I used very guarded language and will never deny that there was zero statistical support for any group. Just like in Brad’s triceps and biceps.
Mike soldiered on, repeating the above a couple of times. The next approach was to say “I’d have to see all the muscles.” They measured two ,rectus and triceps. Yes, rectus showed a non-significant but apparent trend increase. Mike argues “See, the higher group did better.” Christ, we are not talking about the quads.
The entire section was about the triceps. Nobody is debating whether 3,6 and 12 sets should show a better response for 12 for legs, it’s low less low and moderate volume. Triceps was 7 vs. 14 vs. 28 or 6 vs. 18 vs. 30. He repeated this a couple of times. You can see me rubbing my eyes through this bullshit. You can’t argue with this kind of thing, this kind of irrelevant digression. And it is irrelevant. The quad data is not at question. The triceps data is. What the quad data showed for low volumes is irrelevant.
Then I got the “Papers are limited in length” argument. Brad used this too and I already showed that I can rewrite Brad’s misreepresented sentence in less words and represent the data accurately. It’s a non-argument.
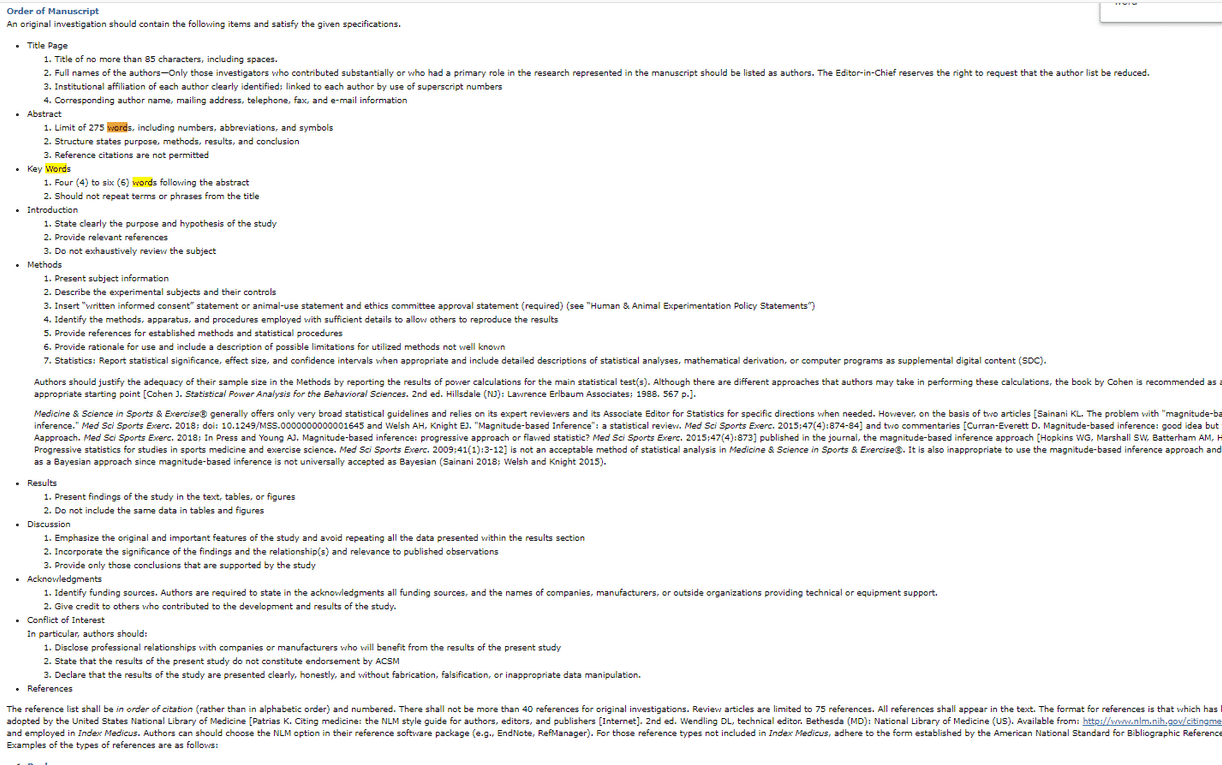
Addendum: Also, this is completely untrue. You can read the MSSE manuscript submission guidelines for yourself. It lists a word limit on the title and abstract and there is NO WORD LIMIT for the manuscript itself. In claiming there was as an excuse for how Brad misrepresented Ostrowski, they are both lying. Well, ok, maybe neither of them knew that was the case. In which case they are both sloppier than I had originally imagined. More likely, they knew full well and figured nobody would bother to check. But it’s not true. And that makes it a lie.
Then the “It’s not the Ostrowski discussion paper”. Oh, c’mon. If a paper disagrees with you it is incumbent to examine why and studies do this all the time. Of course, if you just misrepresent the data in the first place, it’s real easy: no disagreement means no discussion. It keeps the paper shorter and I don’t know why more scientists don’t lie about data this way. If you make every paper agree with you by misrepresenting the data, you can cut paragraphs out of your discussion.
And after several rounds of this I finally gave up. By defining the sentence as not misleading, through the worst kind of semantic game playing, there’s nothing to argue against. You can’t argue against smoke.
In the same way that by defining a study as agreeing with you when it doesn’t, there’s nothing more to discuss.
There was more than that, I’m sure Mike will bring up stuff he threw at me that I addressed. One that comes to mind was my comment about Brad not qualifying anything, how the blinding should have been mentinoed as a threat to validity. He said “But they did address limitations.” I read them outloud, all of them. Not a single one qualified their conclusion or addressed the blinding. See, I can address questions directly. And I did.
The Evidence Based Triad
So among other things, one of Mike’s refrains (other than all science is sloppy so Brad gets to be sloppy and all stats are weak so Brad’s stats can be weak and it’s not a lie so long as you semantically nitpick) was that since these studies are weak they only provide a hypothesis, a direction. I don’t necessarily disagree. But that’s really not at issue. The issue is not of the general scientific method but rather if what was written in this singular paper was valid. My argument is that it was not. Mike’s arguments were mostly deflections.
But once thing that came up in this vein, perhaps in his section is this new concept that is just beautiful. The evidence based practitioner, which used to mean being mostly science based has been expanded. Now it’s science + anecdote + theoretical rationale.
And this is truly gorgeous. Because it means that you can never be wrong. If the science doesn’t support you, fall back on anecdote (like James did). If you don’t have the anecdotes (and the plural of anecdote is NOT science) just argue a theoretical rationale. If that fails, go back to science.
It’s fantastic because it means you can argue anything and everything so long as you can fall back on one of the three. Just keep moving which point you’re on and, at that point, fuck it, throw out all the research. If it’s all sloppy, if sports science is weak, if all studies can be accepted because they can’t bother to do anything right, just break out Arnold’s Encyclopedia and go to town.
Now I’m not saying that experiental data is worthless, that anecdote per se should be ignored. It should be checked against the science that exists and certainly it’s great when science and anecdote correspond (and it often does not). But just because one guy says they got great results doing X doesn’t mean shit. Just like in science, sometimes stuff happens by happy accident or in spite of itself.
Even if 10 people get a result (and the other 99% dong the same thing don’t), that doesn’t mean much. They might be outliers, lying, using steroids, I’m not saying these are the reasons just that they are considerations in this field. Even if they aren’t doing any of those things, the fact is that if 99% get the same results NOT doing it that way, their “anecdotes” mean more than the 1% of exceptions.
I don’t give the first shit that one coach has one female athlete doing 70 sets of back work per week. I say he’s a bad coach and she’s doing something very seriously wrong if she needs that much. Because I can somehow get more than enough back growth out of my female trainees with about 15 sets/week.
She doesn’t need 70 in my opinion, she does 70 because something else about her diet or training is fucked. See this shit all the time, guys doing a zillion sets in the gym not because they should but because they are. And when you teach them to train well, they grow better with less. Because what they needed was not more volume, but to learn how to actually train correctly.
I’m not saying that coming up with interesting theoretical rationales, assuming they have some basis beyond “this sounds good on paper” is worthless. But when you define this triad, it just means that you can be as fucking slippery as Mike was in the debate. You never have to address anything directly because you can always focus on something else.
Summing Up
My actions are not relevant to Brad’s paper.
Other studies limitations are not relevant to Brad’s paper.
That a lot of sports science sucks it not relevant to Brad’s paper.
What got written after the paper was published are not relevant to what was written in Brad’s paper.
Semantic game playing is not relevant to what was actually written.
To whit:
- Not blinding the Ultrasound tech is sloppy science and raises a high risk of bias. Good scientists blind, bad scientists make excuses and so do their defenders.
- The stats didn’t support the strongly worded conclusion by any stretch of anyone’s imagination. Weak BF10 values for 2 of 4 muscles and ZERO P value support. That supports nothing. Certainly not their strongly worded conclusion.
- Ignoring a middle data point deliberately to change the conclusion of a paper is lie. Semanticize it as much as you want but that’s what it is. By representing the data that way a visible plateau turns into more is better.
The End
As I knew full well it would be this debate was a waste of time. We disagreed on almost nothing about volume and I was fairly sure I’d get a lot of smoke but not heat on my issues. I mainly did it so all the “Lyle is too chicken to debate Mike” people would shut the fuck up. And I won’t waste my time on such nonsense again.
Because ultimately nobodies minds will be changed. The people who agreed with me before will agree with me and the people who agreed with Mike will say he owned me. That said, I guess we got something done. I don’t know what but something.
I am serious though, Mike would make a good politician.
By that I mean he has the incredible ability to speak for 10 minutes, avoid the actual question being asked and make people think he said something that wasn’t relevant to the actual topic at hand. It’s a fantastic skill and he’s got it in spades. And people without critical abilities eat it up with a spoon. Watch any politician in the hot seat. Compare the verbiage to Mike in this debate. He’s a fucking natural.
And at the end of the day that 90 minutes would have been better spent having a Valentine’s Day date with myself and Pornhub.
Facebook Comments