So there’s a war brewing in online fitness land. About three weeks ago, Brad Schoenfeld et. al. released a paper purporting to show that more volume meant more growth with 30 sets per week for upper body and 45 sets for lower body outperforming lower and more moderate volumes. To say there has been a shitstorm, much of which is driven by myself, is a bit of an understatement.
I wrote a fairly critical piece about that paper (that had issues, see below) and brought up several other problems with it (including one I will finish this piece with). My questions at Brad or James went completely unanswered with any number of deflections and obfuscations occurring throughout. Even when others, not me, asked similar questions, they went unanswered or were deflected with the kind of behaviors only the best gurus use.
Table of Contents
James Krieger, Just Another Lame Guru
Then, a few days ago, James Krieger wrote an article explaining why different studies find different results to “address criticisms being leveled at the study by certain people (like Lyle McDonald)”. Let me note that I’m far from the only person critical of this paper. But as so typically the case, I’m the only one mentioned by name. And his article was basically just a tedious attempt to ignore the actual questions that I and others have been asking.
So I’m writing a response directly to and at James (others involved in this will get mentioned as well).
For those who want to read it, go here. Let me note that I am providing this link because I feel that it is important for individuals to see both sides of the argument (not that his article has anything to do with what I have asked him. Individual variance within or between studies has jack squat to do with anything I am going to talk about today).
This is called intellectual honesty, something more people in this industry should experiment with. Because somehow, I doubt James will link to my piece any time soon because that might allow people to see MY side of it or see the issues he is so steadfastly trying to pretend don’t exist.
Now some may notice that my original criticism/research review of the study has been unpublished on this site. Here’s why: many of my criticisms were shown to my satisfaction to be incorrect. Let me rephrase that: various individuals showed to me that what I had based my conclusions on were incorrect. I had originally added an addendum to that article and finally just took it down for that reason.
This is also called intellectual honesty. I was wrong, I admit I was wrong, I took down my article.
See how that works?
Again, others in the industry should try it sometime: admitting that they are wrong rather than obfuscating, deflecting and guru-ing to hold onto their belief system or avoid criticisms of their work. Because that is mainly what is going on here. It’s really all that is going on here.
James’ Statistics
I accept that Jame’s statistics were done correctly. I originally said the opposite but I WAS WRONG. See how it works? When you’re wrong, be a man and admit it. Like I said, others should try it sometime.
But let me add, proper statistical analysis of bad data still doesn’t prove anything. The statistics can be done perfectly but if the data is poor to begin with, any conclusions or interpretations can still be poor. Especially when the person (often and in this case NOT the statistician) interpreting the study is trying to (apparently) prove something.
However, these are far from the only problems with the study. Far from it. And what’s interesting is that every time I have shown these criticisms to James, he simply goes back to the statistics. The ones I no longer disagree with and haven’t for weeks now.
It’s like when you argue with someone, perhaps a girlfriend, and have conceded a point 30 minutes ago. But they keep harping on it to avoid the points you’re making now. “Well what you said 30 minutes ago was wrong…” That’s what James (and others) is doing. And the only reason he WON’T address these issues (Brad himself has dodged them constantly or used the most amusing of deflections to avoid them), is because he CAN’T. Because if he could have, he would have by now.
I mean, c’mon. Who doesn’t want to straight up own big meaniehead Lyle McDonald? If Brad had any defense for what I’m going to describe below, he’d have come in and stomped me flat. Instead he guru’d out of it by saying he wouldn’t address my questions because I insulted him.
It’s a deflection plain and simple. Others have done the same telling me to “Learn statistics, idiot.” while ignoring all of the issues I am about to bring up. But the statistics haven’t been the issue I have had with this paper for several weeks. I already said they were ok. Let’s move on.
So in this piece, as a response to James, I am going to once again list my methodological issue with this study along with other issues I have with it. I will make my point, make a bunch of blathering commentary as usual and that will be it. I’m not getting into a back and forth, this isn’t the new rap war. It is however very long. But this is the last thing I’ll say about it.
He made his non-points, I’m making my yet to be addressed points. He hasn’t addressed them, Brad hasn’t addressed them and they clearly aren’t/can’t address them or they would have. A few days back, James hilariously hit me with a laundry list of questions in my Facebook group recently but that’s not how this works. He doesn’t get to ignore my questions and then expect me to answer his.
It’s standard guru behavior and nothing more.
But he wrote his piece and called me out and I’m responding to it and doing the same.
I don’t expect this to change Brad or James’s stance on this paper. They’ve got to keep defending and deflecting and can’t back down now. I’ve seen it before and I won’t be shocked when they either ignore or try to dismiss or obfuscate everything I’ve said in this piece and that’s not my goal.
Note: Hilariously, in 2020, James updated his Volume Bible (pompous much) and admitted that higher volumes have no benefit over lower. He only defended the paper because I criticized it. And now he’s flip flopped and admitted he’s wrong. More accurately, his new conclusions basically can be read as “Lyle McDonald was right all along”. Not that he’d ever have the balls to say it.
The Bottom line: HE’S JUST ANOTHER FUCKING GURU.
This is to get all of these issues out there to let everyone else make their own decision about the situation. About the paper itself AND the individuals involved.
A Brief Sidestep: The Cochrane Guidelines
Doing scientific experiments is not easy and nobody would claim that it was. I’d note that I was involved in a lab in college doing research by Drs. Whipp and Ward. Specifically they were examining the VO2 max response in carotid body resected patients.
I was at UCLA and the hospital had the largest and possibly only population of subjects. I was involved in exercise testing, setting up the breath-by-breath monitors along with data analysis after the fact. So you can spare me the “Does Lyle even science?” bullshit. I also helped with data analysis although I had NOTHING to do with the statistics.
But I saw first hand that doing research is not easy. In the past, a lot of studies were very poorly done in a methodological sense. It still happens today, I even recently saw a paper studying women that didn’t control for menstrual cycle. This is indefensible in 2018. But so are a lot of other research practices: they are indefensible in the modern era.
Because there are actually guidelines in existence regarding good and bad methodology for studies or rather they exist to review if a given study is well done or suffers from various types of bias. Discussion of all of this can all be found in Cochrane Handbook for Systematic Reviews of Interventions which represents the current status of what is considered good and bad study design. I’m mentioning it here as I will come back to it below somewhat repeatedly (I do love to beat a dead horse).
Side Note: Eventually Mike Israetel challenged me to a debate, which accomplished nothing. Among his other hilarious comments was that Cochrane wasn’t suited to exercise physiology. Apparently ex. phys is above bias testing. Which is basically saying “We know our research is shit so let’s just let it keep being shit.” But all of his responses were like that.
The Study’s Methodology
For completeness and since I took my original review down, first let me look at what the study did. First it recruited 45 resistance-trained men who had an average of 4.4 +- 3.9 years of resistance training experience. It was also stated that the men needed to have been lifting for a minimum of 3 times per week for at least one year which is consistent with those standard deviations but let’s not pretend that they were well trained if 1 year minimum was their required training experience. One year is an advanced newbie at best.
The men were randomized to the same workout program which was done three times weekly and did 1, 3 or 5 sets per exercise for 8 weeks. The exercises done were flat bench press, military press, wide grip pulldown, seated cable row, barbell back squat, machine leg press and unilateral leg extension. This yielded training volumes of 6, 18 and 30 upper body pushing or upper body pulling sets and 9, 27 and 45 lower body (ok quadriceps) sets per week.
Of the original 45 subjects eleven dropped out leaving a total of 34 subjects which, as the authors admit, made the study slightly statistically underpowered (they had calculated that they needed 36 subjects). Basically it didn’t have enough people to draw strong conclusions.
My note: this didn’t stop Brad and other from doing just that online and it’s funny that James Krieger is harping on the statistics or making strong conclusions when the study itself was underpowered statistically.
The men had an average weight of 82.5+-13.8 kg although, oddly, individual data for each group was not presented as would normally be the case.
Speaking to their training status, the average 1RM squat was 104.5+-14.2 kg for the 1 set group, 114.9+-26.0 kg for the 3 set group and 106+-24kg for the 5 set group. Let’s call it 110kg for everyone and, divided by bodyweight and that is a 1.3 bodyweight squat 1RM.
That’s 242 lbs at 181 lbs which by standards online is somewhere between novice and intermediate. For bench the numbers were 93.6+-16.1, 96.4+-21.2 and 91.1+-20.9 kg so call it 93 kg average and that’s a 1.1 bodyweight bench. By strength standards online that puts them between novice and intermediate. Like I said, this is hardly well trained. Mind you, if they didn’t do a lot of low repetition training this would be skewed away from a high 1RM. Still….
Their diet was uncontrolled and relied on food records which are notoriously terrible. As well, the reported dietary intakes were more or less impossible as they indicated that each group was in a severe calorie deficit and severely undereating protein. But I don’t think that data means jack squat. It just reflects that diet records are terrible and unrealiable. But few studies can afford to control diet, especially over the length of a study like this so this is just a reality of the research.
Measurements
A number of different things were measured throughout the study including maximum strength improvements and muscular endurance along with changes in muscle thickness. Looking at the latter, the men underwent Ultrasound measurement for biceps, triceps, vastus lateralis and rectus femoris (the latter two being combined into a single measurement and taken as indicative of quadriceps growth which seems a little odd to begin with).
The Ultrasound measurements were done at the beginning of the study and again 48-72 hours after the last workout “In an effort to ensure that swelling in the muscles from training did not obscure results….” I will come back to this.
The study applied several different statistical methods to the data although, once again, I’m not going to get into that in detail since it’s not my area of expertise. In terms of results, the study, at least by statistical analysis suggested that there was a dose response from lower to higher volumes for 3 of the 4 measured muscles. Or that was the paper’s conclusion.
Somehow, triceps shows no significant difference between groups which seems at odds with the rest of the study. Most likely this is due to the study being slightly underpowered statistically. The absolute changes in triceps thickness were 0.6 mm, 1.4 mm and 2.6 mm which would seem real-world significant, but the 2 mm difference didn’t reach statistical significance. The other data is actually similar and you can read another examination of this study here which shows the full changes in each muscle. Note also the large variance in results and the large standard deviations.
For the other muscles measured (triceps, RF and VL), what is called a frequentist analysis (one of the statistical methods used) showed that there was insufficient evidence to conclude that the difference in growth for the 1 and 3 set groups was statistically significant. Basically the low- and moderate- volume groups got statistically identical growth. This seems difficult to take at face value but probably represents the fact that the paper was underpowered.
Only the highest volume group (30 and 45 sets respectively, remember) showed a statistically significant difference from the 1 set group, based on pairwise comparisons. The Bayesian statistics (which I will not pretend to understand but will let a statistician friend address below) described this as “…weak evidence in favor of 3 sets compared to 1 set (BFsub10=1.42) and 5 sets compared to 3 sets (BFsub10= 2.25).” This means exactly what it sounds like, by a different statistical method, 3 sets was weakly better than 1, and 5 sets was weakly better than 3.
The Strength Gains
I’d note that all three groups made the identical improvements in 1RM squat and bench strength (nobody cares about muscular endurance). Do you believe that? That the group doing a mere 13 minute workout three times per week got the identical strength gains as a group doing 5 times that much?
Man, powerlifters would be THRILLED. This goes against literally every study on trained individuals and every meta-analysis ever done on the topic. It fails the reality check so hard it hurts. Especially given the KNOWN relationship between muscle size and strength.
If one group truly gained more muscle than the other, how can they not have gained more strength? Now, ok, the rest intervals were a paltry 90 seconds (chosen out of convenience despite being known to be inadequate) and I’d question who in the hell can squat 8-12RM for 5 sets with 90 second rest to begin with.
They also didn’t do any low rep work. Still, this result is at odds with basically all previous research, reality, and common sense. A bigger muscle generates more force and the lack of a difference in strength gains suggests/implies that there were not actually differences in muscular gains.
The Conclusion
Regardless, the paper’s rather strongly worded conclusion was this:
The present study shows that marked increases in strength can be attained by resistance-
trained individuals with just three, 13-minute sessions per week, and that gains are similar to that achieved with a substantially greater time commitment when training in a moderate loading range (8-12 repetitions per set).This finding has important implications for those who are time-pressed, allowing the ability to get stronger in an efficient manner, and may help to promote greater exercise adherence in the general public. Alternatively, we show that increases in muscle hypertrophy follow a dose-response relationship, with increasingly greater gains achieved with higher training volumes. Thus, those seeking to maximize muscular growth need to allot a greater amount of weekly time to achieve this goal.
They don’t say that it may or that it might. They state that it does show this relationship. Shows. As in the case is closed. Before looking at the rest of my issue, let’s look at that strongly worded claim first and see if it is warranted.
Oh yeah, in the debate Mike Israetel argued that the above was not a strong conclusion because it didn’t list set counts. But, well, jesus fuck.
A Quick Look at the Statistics Above
I’ve made it abundantly clear that I am no statistician and my earlier mistake was talking outside of my area of knowledge which won’t happen again. But I happen to know a very good statistician (he has asked both James and Brad pointed questions about the paper with about the same non-response I have gotten). I asked him to interpret the above and this is what he said:
In order to support their unqualified claim of “increasingly greater gains achieved with higher training volumes” instead of, for example, leaving open the possibility of a plateau between 3SET and 5SET, they would need to have substantially good evidence.
In the Frequentist, or classical, analysis, none of the three metrics with pairwise comparisons demonstrated a statistically significant difference between 3 SET and 5 SET groups, and triceps didn’t even make it to pairwise comparisons. If the analysis stopped at the classical analysis as reported in most research, there would be zero statistical evidence for 5 SET over 3 SET.
In the Bayesian analysis, the evidence from the triceps results “favored the null” (weakly), meaning no difference in groups, and the other three metrics favored 5 SET over 3 SET, also being “weak evidence.” So, what does “weak evidence” really mean? Well, Harold Jeffreys originally developed some guidelines (not to be used as hard thresholds), and he described Bayes Factors between 1 and 3 as:
“not worth more than a bare mention”
MY NOTE: the Bayes Factors were 1.42 for 3 vs. 1 set and 2.25 for 5 vs. 3 sets.
Others have shortened this description (weak, anecdotal), but the point remains the same. Trying to use this weak level of evidence to support an unqualified conclusion is a hell of a lot more than “a bare mention.”
Basically, the people who developed these statistical methods take a weak difference to be not worth more than a bare mention. And certainly not worth the strong conclusion made in Brad’s paper that a dose-response relationship in favor of the highest volume of training existed.
The bottom line is that the paper’s statistics didn’t support the conclusion. And I can assure beyond assure you that if a paper Brad and James disagreed with had had such weak statistics, they’d have dismissed it. Cute, eh?
So with that taken care of, let’s look at other aspects of this study that I think are problematic, absolutely NONE of which have to do with the statistics.
So let’s stop bringing that up as a deflection, shall we James?
A Lack of Body Composition or Even Weight Data
As I mentioned above, the study provided initial anthropometrics in terms of height, weight and age. As I noted above, this data was not presented, at least in the pre-publication paper for each individual group (i.e. weight, height and age for the 1-set vs the 3-set or 5-set group) which is atypical. Usually you show individual values for each group or at least mention if they were not different between groups.
Far more oddly, post-study weight was not measured, or at least not provided in the results. This is a bizarre oversight and I can’t recall any study in recent times that did not present pre- and post-study weight along with showing how it changed for the different groups. I mean, put ’em on a scale before and after, boom, done. Takes about 30 seconds before you do the Ultrasound. But they only did it before apparently. No reason is given for this.
Nor was any measure of body composition done. Now, this could have been purely a money issue or a time issue but most studies will put the subjects into a DEXA machine to get body comp so they can examine changes in lean body mass/fat free mass (LBM/FFM) and body fat percentage.
Let me make it clear that changes in LBM/FFM are NOT a good indicator of muscle growth. We all know that you can carb-load or carb-deplete someone or just have a big poo and that changes LBM. However, it does provide some useful information on other aspects of the study.
For example, it can tell us indirectly about diet. So if one group gains weight and fat and another loses weight or loses fat, you can infer that the first group was in a surplus and the second wasn’t. In the context of a muscle growth study, and given the absolutely terrible accuracy of diet reports (and the literally impossible food records of the subjects in this study), this is good data to have. If one group was eating enough and the other wasn’t that can color the results pretty enormously. But this study did not have it. Again, might have been technical, time or financial and this isn’t a deal breaker per se.
The total lack of post-study bodyweight data is however baffling (a search for “weight” on the PDF turns up 4 hits and only one deals with bodyweight which was the initial numbers). Even if the only data it provides was that the 1 set group lost weight and the 5 set group gained it, that would give us SOME indication of what was going on diet wise. Given the impossible to believe diet reporting records, this would have been good information to have. Nope, nada. Again, an absolutely baffling omission given how unbearably simple it is to measure and report.
A Primer on Ultrasound
While DEXA or other body composition measurements were often used in earlier studies, the current optimal method to measure changes in muscle thickness is Ultrasound which this study did use. It’s a much more direct measurement of thickness, bouncing sound waves off of tissue and providing a visual representation, it’s how they check on fetal development for example.
The thing is, it’s not perfect. Yes, there are specific guidelines to follow for anatomical places to put it and that’s all fine and folks get trained on it as well but Ultrasound has a bigger issue which is that the interpretation is subjective because the image being obtained is something like this:
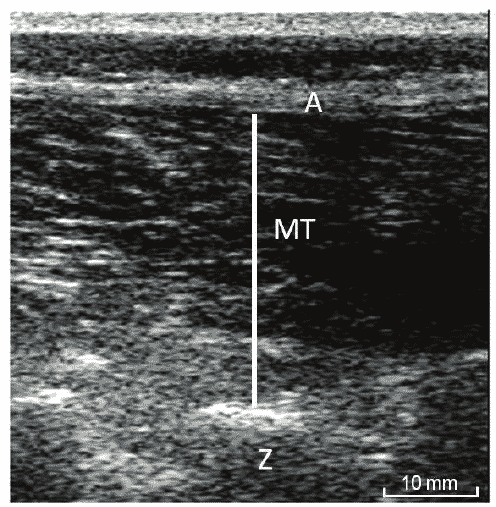
And as anyone who does Ultrasound in a hospital will tell you, there is a huge subjective component and two Ultrasound techs might come up with completely different results (which is why you have two people do it, to compare results). Some of this improves with experience or they wouldn’t use it in a hospital setting but often you are getting sort of a vague image that you have to interpret. This introduces the potential for bias.
Note: Brad’s name is on a paper basically pointing out that Ultrasound is subjective and that research needs to be really clear on what it’s measuring. Translation: he wants everybody else to do better science. He can’t be asked.
That is, say the ultrasound operator knows what they want to find. They might interpret the image differently than someone who is just looking without that bias. So an alcoholic goes to a hospital and gets and Ultrasound on their liver. If the tech expects to find a damaged liver, it can color what they “see” on the Ultrasound monitor. If they are just told to do the Ultrasound, their interpretation may be less biased.
I’m not saying this happened in this study that the Ultrasound tech was necessarily looking for a given result, well I’m not saying it yet anyhow. I am saying that there is the potential for it to occur due to the subjective nature of Ultrasound to begin with. This problem can be avoided in numerous ways, the simplest being to have two people measure the same subject so they can see if their results match up. But this becomes a real problem when combined with the next issue.
Let me note, many studies run by competent scientists blind the Ultrasound tech. In d, I list several study titles and show that they were blinded. It can be done. More importantly it should be done. And yet Brad has NEVER done it.
The Study was Unblinded
So let me explain what blinding a study means and why it’s important. To blind a study means that someone, either the subjects, the researchers or both do not know who is in which group. If you only blind one group it’s called single blind, if you blind both it’s called double blind (if you poke everybody in the eye, that’s called triple blind and yes that’s a joke). You can actually blind more folks than that. The folks doing the statistics might be blinded, for example. Or any number of people involved in the study. But why does this matter?
Blinding the Subjects
Imagine a drug study that is studying drug X and a placebo and you want to measure some outcome. You make the pills look identical (so folks can’t compare or know which is which) and then randomize people to one group or another and keep a sealed record of it. So someone knows that subject 1 got the drug, subject 2 got placebo, subject 3 got placebo or whatever. You just give everybody a number and someone has a super-secret handbook that says who is who.
But the subjects ideally don’t know if they got the drug or the placebo. This is critical because if the person knows what the drug is or is supposed to do, that can color what happens. We’ve all seen that episode of a TV show where kids get drunk on non-alcoholic drinks. Or pretend to be. Their expectations make it happen. If give you an aspirin and tells you it’s the most potent German steroid ever, I bet you’ll be stronger in the gym. Pure expectation.
If you’re doing a study where the drug is supposed to improve health, if one group knows they got the drug and the other a placebo, they might adopt (even subconsciously) other health promoting behaviors that skew the results. If someone enters a drug trial hoping to get the newest drug for a given situation and knows that they didn’t get the drug, they not take the pill or care about the results.
You blind the subjects to the drug to prevent that from happening and hopefully have everyone take the pill without expectations or change in their behaviors so that you’re measuring the effect of the drug itself.
Blinding the Researchers
But why would you blind the researchers? For the same reason: expectations and bias. Let’s say I’m overseeing a study to see if caffeine improves performance over placebo during an exercise test. First we bring the subjects in and exercise test them.
Usually some amount of encouragement goes on here to get a truly maximum effort, you yell and holler at them (we did this with the carotid body resected patients I helped to study at UCLA) until they give up. Now let’s say that they are blinded to whether they got caffeine or the placebo. They don’t know what they got. So they have no expectations to color their effort and hopefully everyone goes all out.
But let’s say I know who got which compound. That is, they are blinded but I’m not. Let’s also say that I already believe that caffeine improves performance (I do and it does). Now we re-exercise test them. I’m in the room and I know who got which compound. Now my pre-existing belief or expectation can subconsciously or consciously make me act differently.
Perhaps I give the caffeine group a little extra encouragement or the placebo group a little less. I might not even notice I’m doing it but we are just humans after all and we’re all subject to this. If/when this happens, I may simply end up proving what I already believe to be true because my motivation may get them to improve by 3%. But it will look like the caffeine. I probably won’t even know I’m doing it and I’m not saying it will be deliberate. But humans are great at deluding themselves into thinking we are free of bias and purely objective.
In contrast, if I don’t know who got what (I am blinded to who got what) everybody gets the same treatment during the exercise test and I can reasonably assume that the data is good. Alternately, if I’m the head researcher, maybe I stay out of the exercise room and have someone else who is blinded administer the test. They might not even know what the study is about so they just scream and holler equally at everyone.
They can’t have expectations if they don’t even know what we’re studying or if they don’t know who got what compound. We get the data, break open the chart showing who got what and boom, we have good data. Caffeine did this, placebo did that. And it was double blinded so nobody had an expectations. Not the subjects, not the researchers.
Blinding Everybody
We might additionally blind the people doing data analysis so they don’t know which data came from which individual. Often data in research studies is messy, it was in the Vo2 max data was collected on the carotid body resected patients when I was at UCLA. If the data analysts aren’t blinded to who is in which group, THEIR expectations might colors how they analyze the data. They know what the data is “supposed to look like” and that can color their judgement.
Get it? Blinding is critical to avoid a risk of bias in studies, bias of the researcher, subjects, data analysts, etc. coloring how the data is gathered or examined. I am not saying that not blinding makes any of the above happen. I am saying that it can. And that blinding reduces that risk.
Blinding the Reviewers
Hell, once the paper is done and goes into peer review (where experts in a given field are allowed to critique the paper and even disallow it until problems are fixed), you could (and probably should) blind the reviewers from the researchers. That is, the reviewers shouldn’t know who wrote the paper.
To understand this let me explain peer review. Basically research papers, at least in reputable journals, are put to the test by a variety of peer reviewers, presumably experts in that area, to look at the paper critically and identify problems or areas that should be fixed.
For example, months back Brad asked me if I’d be a peer reviewer on a paper about PCOS, elevated testosterone and training. Keep this factoid in mind if Brad attempts to dismiss my experience or knowledge in the field since he contacted me specifically to be involved in this. Given my work on The Women’s Book, I was a logical choice.
And in this case, I saw a problem with the paper (having to do with the levels of testosterone in the subjects) with it and reported it to the researchers. The researchers responded and since their response (with research provided) was sufficient to allay my doubts and I gave my approval the paper. Other reviewers do the same and the paper has to be done or written to the approval of all reviewers to pass peer review and get accepted and published.
But in an ideal world, the reviewers probably shouldn’t know who wrote the paper as it could bias them either positively or negatively. So consider a researcher who has established themselves as a name, publishing often (and presumably well). Any work they did might be looked at less critically than someone who was either unknown or who the peer reviewer actively disliked for some reason.
Ideally, the paper’s author should probably be blinded from the peer reviewers, that is they should be anonymous. There is an immense amount of politics in research and if an author found out that a given individual was especially critical of their paper, they might retaliate in some way.
This apparently does occur from time to time but I do not know how prevalent is. Honestly, it should probably be standard operating practice. A previously well published and meticulous researcher can still produce poor work and their work should be assessed on the work rather than their name. That requires blinding of the reviewers . But this is sort of a side point for completeness about the idea that various types of blinding are critical to reduce bias in all manners of ways. I will only focus on blinding during the study itself going forwards.
Back to Cochrane
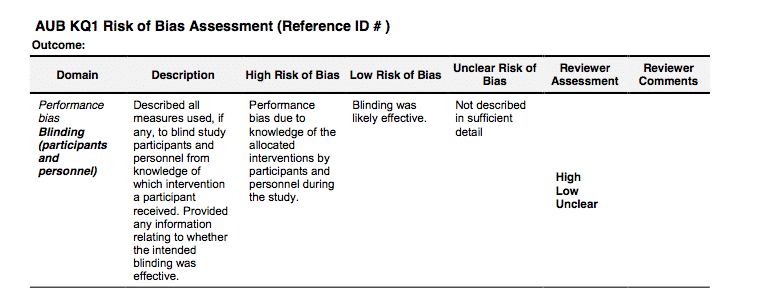
And I spent all this time explaining how blinding works and why it is necessary because a lack of proper blinding during a study is listed in the Cochrane guidelines as providing a high risk of bias. This is a partial image from this link (note, clicking will download a PDF) and shows that a lack of blinding of participants and research personnel gives a high risk of bias according to Cochrane standards.
Blinding the Subjects in Brad’s Study
Now in a training study, you can’t completely blind the subjects to what is going on. Clearly everyone knows whether they are doing 1,3 or 5 sets per exercise or doing continuous or interval exercise. That’s just a reality that you can’t get around (you can in drug trials by making both pills identical). At best you might partially blind them.
You might not tell them the purpose of the study (i.e. to measure muscle growth) or you could tell them that you were studying something else. If they know it’s a study on muscle growth, maybe they change their diet, for example and their diet or supplement regimen might change. Studies do this fairly often, deceive the subjects about the purpose of the study to try to eliminate their own expectations or subconscious behavior changes.
Alternately, you might not tell them that there are two other groups doing different volumes within the same study. This could avoid a situation where someone in the 1-set group simply didn’t work as hard since they weren’t in the “real training” group doing 5-sets or something.
Given that Brad’s training studies typically have the workouts overseen by trained individuals, this is unlikely to have occurred. But maybe they only believe in high-volume training and don’t pay as much attention to their diet. I am not saying this happened. I am saying that it CAN happen when you don’t blind a study to the best of your ability.
Mind you, it’s a bigger pain in the ass to do this. You’d need to meet with each group individually, give them different instructions and train them at different times in the gym which adds another variable. But it could be done with a little bit of work. It wasn’t but it could have been.
Blinding the Research Personnell in Brad’s Study
But that doesn’t mean you can’t blind the researchers in this case. And, quite in fact, you should for all of the reasons I listed above. And this was not done in Brad’s study (a PDF search for the word “blind” or “blinded” turns up zero hits). It’s possible that the study was blinded and it wasn’t mentioned in the methods but this would be utterly atypical. It turns out that the study wasn’t blinded and Brad admitted online that it wasn’t.
Note: when I did my analysis of other papers on volume and hypertrophy, I took no mention of blinding to mean that they were not. That is, I am consistent in my assumptions.
Basically all of the researchers, including the person doing the Ultrasound were not blinded to which subject was in which group. They knew that this subject was in the 1 set group and this other subject was in the 5 set group beforehand. If the Ultrasound tech had a pre-conceived belief about what results they expected (or ahem, wanted), this introduces a high risk of bias according to Cochrane guidelines. They might measure or interpret the 1-set group a little bit differently than the 5-set group. When you’re dealing with a subjective method this is a real issue.
Am I saying this caused a bias in the measurements? Well, not yet. But a lack of blinding, a shown in what represents the highest tier of research analysis, says that it introduces a high risk of bias. Simply, blinding a study reduces that risk and is what good scientists do.
Could bias still occur? Sure, probably. But that’s a non-argument, a hand-wave that could be leveled at any study you didn’t like. Not blinding a study gives a high risk of bias, blinding it does not. A good scientist trying to gather good data would blind the study to the greatest degree possible to reduce the risk of bias to the greatest degree possible.
And Brad and the others did not do this leading to a high risk of bias.
Adding to this is the following issue.
Who Did the Ultrasound?
So that nobody can accuse me of misrepresenting anything, here is a screenshot from the pre-publication text regarding the Ultrasound measurement and who it was performed by.

It states clearly that the lead researcher did the Ultrasound. And who was the lead researcher?
Brad Schoenfeld.
He and he alone did Ultrasound on every subject before and after the study.
Let me say that again, louder.
Not only was the Ultrasound done by exactly one technician (meaning that results couldn’t be compared between two different people for accuracy) it was done by Brad himself.
Who, due to the unblinded nature of the study, KNEW who was in which training group. When he did the measurements, he knew when he was measuring someone from the 1-set, 3-set or 5-set group. Am I saying this biased him? Well, not yet. I’m saying that having a single researcher, who is the lead researcher doing the measurements in an unblinded situation yields a staggeringly high risk of bias. Especially if that lead researcher has a pre-conceived believe about the relationship of training volume and muscle growth.
All Brad had to do was follow the Cochrane guideline, a guideline that all good studies try to implement, and that would have eliminated even the possibility of bias. And he didn’t. You can’t claim he didn’t know, he’s far too experienced a researcher to not know that proper blinding reduces the risk of bias. So I have to conclude that it was a very deliberate choice. There’s no other logical reason not to have blinded it at the minimum and had other blinded techs do the measurement at maximum.
But it gets worse.
Responding to Online Criticism
When Brad was asked about this online, why the study was unblinded and he did the measurement himself and didn’t that potentially color the results, he basically said “Oh, it’s fine, you can trust me.” First off, this confirms that the study wasn’t blinded to begin with or he would have said “Oh, no it was blinded.” The study wasn’t blinded by his own admission and he knew who was in which group. By the highest standards of research critique, this introduces a high risk of bias.
And he says that’s fine because you can trust him which, well…really? Because I’ve looked at that chart from Cochrane a bunch of times and nowhere does it say that a lack of blinding is a high risk of bias UNLESS YOU’RE BRAD SCHOENFELD WHO CAN E TRUSTED.
You can read it yourself above and tell me if I missed it.
But this raises important questions about science and the scientific method:
Is Brad the only trustworthy researcher in the world? Why can’t we just trust everybody else? Why blind studies at all if it’s as simple as trusting the guy doing the research? Why have guidelines of any sort to begin with? Why bother with Cochrane? Researchers never try to push an agenda or publish false data. You know, like Andrew Wakefield who did that fake vaccine and autism study that is still causing problems now.
Nah, Brad is different. Brad is above the scientific method. You can trust him. He said so.
Brad further tried to argue that you can trust him because he disproves his hypotheses all the time. I’m not going to bother trying to explain what this means since it’s a non-argument, just another obfuscation from someone who got caught out.
Because it still wouldn’t explain why Brad thinks he is above Cochrane guidelines, literally THE standards for scientific of inquiry and study review (and note that there are other bias tools and not blinding the outcome assessor is always a source of bias).
Basically he’s saying that he and he alone doesn’t have to follow scientific standards, that he is above the law that all other good scientists follow. It’s a shame that all of those other scientists don’t live up to his standards. Oh wait, I have that backwards. He doesn’t live up to theirs because they know to blind their studies and he thinks he doesn’t have to.
So am I accusing Brad of bias? Not yet. I’m saying that by the standards of scientific inquiry, a lack of blinding raises a high risk of bias. If someone else had done the Ultrasound unblinded, it would have been bad enough. Brad doing it himself do it is worse. Brad’s attempt to defend not blinding his study by saying you can trust him is just a joke. But not the ha-ha kind.
Oh, you want hilarity. A recent review paper came out on the topic of protein intakes in hypertrophy. In it, several papers were thrown out after a bias asessement was done. Two of them by Dr. Jose Antonio were thrown out because they were not blinded. Oh yeah, Brad and James’ names were both on the paper. Funny, huh? But I guess not blinding the assessor to the outcome is only biased when it’s anybody but Brad Schoenfeld.
The Time Point of the Ultrasound Measurement
As I stated above, the post-study Ultrasound (done by Brad who knew which subjects were in which group) was done at 48-72 hours after the last workout. It’s unclear if this was done for practical or other reasons (i.e. insufficient time in a single day) but it introduces another potential variable to the study.
So why not get two techs and do it all on the same day? And maybe blind them to who was in which group. Ideally you get both to measure all subjects and compare the two values and now you have data that is not at a high risk of bias. Because measuring subjects on two different days after the final workout introduces another set of problems and another variable. Because now we have to worry about whether or not the time of measurement might be impacting the measurement itself.
As I stated above, the paper choose to wait 48 to 72 hours after the last workout to do Ultrasound in an attempt to ensure that edema and swelling from the workout had dissipated (said edema showing up on the Ultrasound as growth). In support of this, they cite the following paper (although they got the reference number wrong).
This is an interesting little paper which had trainees do 3 sets of nothing but bench press 3 times per week for 6 months and measured growth in the pecs and triceps by Ultrasound (this makes me wonder why pecs aren’t measured more often since it can clearly be done and would give more information than doing compound chest work and measuring triceps in isolation and inferring anything about training volumes).
In the discussion from this paper it is stated that:
“Measurements were taken a week prior to the start of training, before the training session on every Mon- day, and 3 days after the final training session. Pilot data from our laboratory suggest that the acute increase in MTH (~12%) following bench press returns to pre- exercise levels within 24 h and is maintained for up to 48 h after the session. This suggests that the measured MTH is unaffected by the exercise-induced acute in-flammatory response although it is acknowledged that is an indirect marker of muscle damage. The test–retest re- liability for this method was less than 1% for the biceps and triceps [10] “
So this seems to support the claim that edema is gone at 48 hours but there is a problem. This study only had 3 sets for bench in the final workout and there is exactly zero indication that the same would hold for higher volumes than this. I’m not saying they will or they won’t, there’s not much data.
Regardless, the Ogasawara study can’t be cited or used automatically to assume that a higher volume doesn’t generate swelling that lasts longer. Of some interest in this regard, in his own textbook, Brad states the following:

If you didn’t click the picture, it says “Although swelling is diminished over time with regimented exercise via the repeated bout effect, substantial edema can persist even in well-trained subjects for at least 48 hours post-workout.” The phrase “at least” means it might last longer but we know for a fact that it’s still present at 48 hours after an intense workout. IN TRAINED INDIVIDUALS.
But it was certainly present at that time point. This means that Brad measured (in an unblinded fashion by himself) muscle thickness at a time point that, per his own textbook, edema might still be present. Said edema skewing Ultrasound values upwards artificially. Hmm….
Other Edema Data
There is other data of relevance here and it’s interesting that it wasn’t cited. In a 1994 study, Kazunori and Clarkson subjected beginners to 24 eccentric contractions of the biceps (this is a heavy load to be sure and I’m not saying it’s comparable to relatively trained individuals not doing pure eccentrics) and then measured muscular swelling at 1, 3, 6,10, 23, 31 and 58 days afterwards. Perhaps shockingly, they found that muscle swelling was the lowest (equal to or lower than post workout) the day after training and only started to increase again at day 2 through 5. I’ve presented their data below.
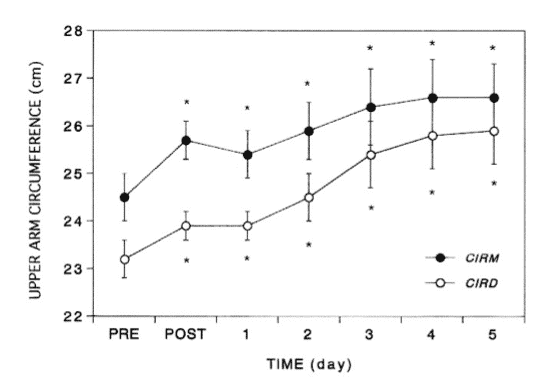
This actually suggests that the BEST time to measure muscle thickness would be the day immediately after the last workout and that waiting longer than that allows inflammation and swelling to increase, continuing to increase until day 5. Of course this was in beginners and there’s no way to know if it would apply to trained individuals. Also pure eccentric work is not the same as regular training so this is no more directly comparable to Brad’s study than the paper he cited.
Speaking to this, Ahtiainen et. al. exposed trained men to 9 heavy sets of leg training (5X10RM leg press and 4X10RM squats) while measuring swelling and thickness in the Vastus Lateralis at various time points. It found that swelling had increased at 24 hours but was still clearly present at 48 hours (the swelling caused and increase in apparent muscle thickness of the vastus lateralis of +2 mm at both time points). That is with only 9 sets of heavy legs which can be contrasted to Brad’s highest volume group at 15 sets and it’s clear that edema is still present at the 48 hour mark.

Therefore it’s pretty safe to assume that doing Ultrasound at 48 hours was not only LIKELY to have been but absolutely WAS impacted by edema and swelling in the tissue. Unfortunately, none of the above is dose response so we still don’t know if the amount or time course for edema varies for different volumes.
The bench press study was only 3 sets, the eccentric study might not be applicable and the above study was 9 sets. Will 12 sets cause more edema? What about 15? Is there an accumulation of edema with multiple workouts per week for the same muscle group? We don’t know.
Now, if the increase in edema is identical irrespective of volume, it’s at least a consistent error and would have applied to all training groups. Mind you, this seems unlikely, that 3 sets and 15 sets for quads would generate identical levels of swelling. But we just don’t know.
Regardless, 48-72 hours is the wrong time to try to measure real-world changes in muscle thickness (and Brad’s own textbook supports that). Edema is known to be present and you can’t claim that you waited 48-72 hours to let edema dissipate when it is clearly still present and cite a study that isn’t really relevant due to the low volume of training used. And ignore a different study in your own textbook that says that edema is still present at 48 hours.
Ultimately, even with the limited data there is absolutely no evidence in literature to conclude that swelling would be absent or insignificant at 48 h for all but the lowest volume of training. Measuring any group with Ultrasound at this time point will be impacted although we still don’t know if volume has any effect on how much swelling is present.
Of some note, other research groups, ones that blind the outcome assessor measure Ultrasound later, up to 5 days after the last workout. This is called doing good science. Something Brad and James, despite their exhortations don’t know how to do.
There is another point worth noting which is that in Ahtiainen et. al. study the magnigude of change in muscle thickness due to swelling is similar to the overall magnitude of change seen in Brad’s study to begin with. Given that edema was likely present, it’s impossible to conclude that there was actual muscle growth in any of Brad’s groups. Or that it was different in any case. Measuring at a time when edema is clearly still present makes it impossible to know for sure. But it makes the data questionable.
But you say, some people were measured at 72 hours. Well as the Kazunori and Clarkson study shows, swelling actually keeps going up from 48 to 72 hours, at least in beginners (sadly the second study didn’t measure past 48 hours which would have been fantastic data to have).
So in either case, irrespective of the groups involved, doing Ultrasound at these time points makes the data potentially very unreliable. All groups were measured when edema was still present and it’s possible that it was still increasing at 72 hours. It’s difficult to understand why this would have been done to begin with given the (admittedly) limited literature on the topic.
I’ll reiterate that it’s completely unclear how volume impacts on this. We certainly can’t assume that the amount or time course of the swelling is the same for higher and lower volumes of training. I’m not saying that it is or it isn’t. I’m saying that WE DON’T KNOW. We certainly can’t assume that a study using a low volume of training necessarily applies to much higher volumes.
In Brad’s study The 1-set group did 2 total pushing sets, the 5-set group 10 sets. Think about the difference in pump you get from different volumes. It’s no stretch to think that inflammation and swelling is still present. Again, I’m not saying it is or it isn’t. We simply don’t know. It’s no more accurate for me to say that it was than it would be for Brad to say it wasn’t. We don’t know. But until we know, any measurements taken at these time points are suspect.
The Huan et. al. Study
I’d note in this vein a recent study by Huan et. al. that came out about 3 days before Brad’s paper showing that, above about 20 sets per week, there was a huge increase in extracellular water compared to the lower volumes. This threw off the supposed LBM gains because at the higher volumes the measured LBM gains were primarily water.
But it is suggesting that, above a certain volume, the body starts to retain water in tissues and this doesn’t occur at lower volumes. I don’t know if that would impact the Ultrasound measurements or not but it does raise another consideration here.
Only the highest volume of upper body work crossed the 20 set threshold in Brad’s study although both the moderate and high volumes for lower body crossed it. Without measuring ECW or correcting for it, there’s another potential problem with comparing set volumes in this fashion as this might have thrown off the values further.
If the higher volume group got more water retention/swelling than the lower volume group, that colors the supposedly greater increase in muscle size. Again, I’m NOT saying this happened. I am saying that we need to find out how much of supposed changes are due to factors other than changes in muscle thickness before any more research is done or we draw conclusions that are measuring at a time point where edema is a known issue.
Do a Pilot Study
Honestly that is data that should be gathered before another study using Ultrasound is done. Find out exactly when it’s safe to re-measure muscle thickness after the last workout to get an accurate reading and do it for different volumes of training. Test a bunch of people on 1 set per muscle, 3, 5 10 and measure them every day for a week (or until the edema dissipates) to determine the time course of the swelling and when it is gone. Because if it’s longer than 48 hours a lot of studies have a lot of potential problems.
This is what pilot studies are for, to examine issues of methodology for a research project BEFORE you do that project to make sure what you’re doing is valid. Citing potentially unapplicable studies is not the sign of a detail oriented researcher. And it’s funny how many studies cite that same Osawagara study above using literally the same verbiage. It’s like they all have the same Madlibs paper program.
Doing measurements at a time where it’s clear that there IS still swelling is methodologically unsound. Doing it at two different time points, when it’s totally unclear how much swelling does or does not change is worse as it introduces another variable into the overall equation. As above, it might have been a purely practical issue. But it is an issue.
Yet Another Ultrasound Issue
But there is yet another issue. The paper gives exactly no indication of who got measured at what time point. Ideally this would have been randomized (as the subjects initially were to each group) but, if it was, this was not stated in the paper. Given that the randomization of the subjects was mentioned explicitly, I have to infer that randomization was not done for the post-study Ultrasound. I may be wrong about this and someone can correct me if I am. This is simply my inference based on how the paper was written.
Why is this important? Well, what if edema goes down at 72 hours, especially for lower volumes. But doesn’t at 48 hours. Or that at 48 hours the highest volume is still swollen but the lower volume isn’t. That alone causes a problem because who got measured when changes the reliability of the results.
But to this we add that Brad knew who was in which group since it was unblinded. What if, by accident or design, the higher set groups got measured at the 48 hour mark (when edema is KNOWN to still persist) and the lower volume groups got measured at 72 (when it might or might not for lower volumes)? Then you get a systematic error in favor of who got measured at 48 hours and they will get larger apparent growth due to the edema.
I’m not saying this happened. I am (repeatedly) saying that when you don’t blind a study and don’t randomize who gets measured when, the risk of bias is enormous. And saying “You can trust me” doesn’t make that bias go away, it makes you question the person who said it and why they think they are above current scientific gold standards.
You blind for a reason. You randomize for a reason. You don’t measure on two different times points when you don’t know what edema is like. Good scientists pay attention to these factors.
An Easily Solvable Problem that Wasn’t
The entire issue could have been dealt with easily. First, get two Ultrasound techs, neither of whom are Brad and blind them to who is in which group. If possible, have them measure everybody on the same day, eliminating the variable of 48 vs. 72 hours. Ideally have them both measure all subjects for accuracy for inter-tester reliability.
If that’s not possible, at least randomize the subjects to the 48 or 72 hour time point so that there is a spread of who gets measured when. At the very least, if Brad is doing one set of measurements, get a second tech to do a repeat measurement to test for reliability between the two. Blind both and randomize the subjects. This provides more validity when you’re using a subjective method. Seriously, this is research methods 101 and anyone trying to design a valid study knows to do this stuff.
But having the lead researcher, who is not blinded to who was in which group measure everybody at two different time points introduces far too much bias. Again, I’m not saying it was there or deliberate or conscious. I am saying that Cochrane standards EXIST to help avoid bias. A simple blinding of the study would fix it. Without blinding, the risk of bias is high. Add in all of the other variables and I’d say it’s almost guaranteed.
Oh yeah, when I emailed Brad about this he got really defensive telling me he was a “seeker of the truth”. Methinks thou doth protest too much, sir. If you want to seek scientific truth, follow the established scientific guidelines. And when questioned on why you didn’t, don’t guru out of it and claim you’re above the law.
Moving on.
Are Brad and James Biased?
Before pulling the trigger and presenting the smoking gun on all of this, let me address something I’ve been hinting at above when I keep asking if I am accusing Brad (or anyone else involved of this) of bias. I kept saying no, not yet and well, it’s time for me to do so directly.
In 2017, Brad wrote the following paper (actually a letter to the editor I believe) with Ogborn and, hey, what do you know about that, James Krieger is a co-author, titled:
The Ostrowski Data
And finally is the smoking gun, honestly the only part of this that really matters. And the one that only James has had the balls to even attempt to address, even though he did it appallingly poorly. Brad ignored it, others deflected it, one person I trusted blindsided me completely with something I wrote 9 freaking years ago on a blog post (said post has since been corrected and it would have been lovely for him to have let me know about this sometime in the past half decade instead of saving it as ammunition for when he needed it against me). Israetel of course defended it but he should be in politics with his ability to speak for 10 minutes and say nothing.
I’m choosing not to name him for my own reasons but he’s just as culpable in all of this mess since he’s doing the same type of defenses of this as the others. He’s done other things, trying to draw distinctions between this paper and another based on training status but the subjects in this study were NOT well trained. So it’s just another pathetic deflection.
Nobody involved has yet to address the issue directly. And even having written this very thing a bunch of times, they still won’t.
That’s because they can’t. You’re about to see why.
Writing Discussion Sections in Scientific Papers
In scientific studies, in the discussion, it is standard to examine other studies looking at the same topic whether they agree with you or not (in the introduction you usually give a precis of previous work). You might note that in my books I will often mention when studies are contradictory as it’s important to present both sides of a given topic. This is called being intellectually honest. Doing this, looking at the body of literature on a topic allows good scientific models to be built. So you look at previous studies and address them.
Did your study’s results agree with the broader body of literature or did it disagree? Or rather, did a given study find results similar or in contrast to yours? If the latter, it is incumbent upon you to address why the results might differ.
Often it’s methodological. A training study on beginners and one on more advanced trainees should get different results based on training age. Training to failure, frequency of training, total volume, a lot of factors can impact on why two training studies get different results.
But if one study on beginners get results so far out of the realm of the dozens of other papers, odds are that that single paper has an issue (consider that if a paper came out tomorrow saying that gravity didn’t work, it would go against hundreds of years of data and is likely incorrect). Now maybe your contrary paper is correct and represents a novel finding which should be incorporated into or improve the current scientific model.
But you have to address it in any case and try to at least speculate why your results were different from the broader body of literature if that was indeed the case. If their results were similar, you can basically say that your results were similar which adds to the body of literature concluding that X leads to Y (i.e. dropping something off a building leads to it falling at the speed of gravity).
And more importantly, you have to report the data on a study, especially if it runs counter to your results, honestly. Now in part of the discussion, Brad actually did this for the strength data, examining why his results (no strength gain difference between groups) ran counter to literally every other study and meta-analysis on the topic. I’m not being hyperbolic here.
The relationship of training volume and strength gains is extremely well established and, except in rank beginners, higher volumes give better strength gains than lower at least up to a point. Yet Brad’s 1 set group got the same strength gains as a group doing 5 times the volume over 8 weeks.
It stands in complete and utter contrast to the broader body of literature. And after addressing that his study was different, Brad reached exactly zero conclusion as to why this was the case (this didn’t stop him from crowing to the New York Times about how little training is needed for strength gains. ONLY 13 minutes! Great soundbite. Only true in beginners.).
Personally I think it’s super easy to explain. Given the known relationship of muscle size and strength, the lack of difference in strength gains was due to there being no meaningful difference in muscle growth. Occam’s Razor says the simplest explanation is the right one and the simplest explanation is that the higher volume group didn’t gain more muscle or they would have made better strength gains. Regardless, Brad did honestly examine the difference between his study and literally 60 years of contrary data even if he drew zero useful conclusion beyond “We dunno.”
It’s on the muscle growth data that the real problem shows up. In the discussion of their paper, Brad examines a previous paper on the dose-response of training and hypertrophy to compare it to their results (recall that Brad et. al. claim that the highest volumes were the only ones that generated meaningful growth and did so strongly in their conclusion despite the Bayesian statistics absolutely not supporting that conclusion as they were ‘not worth a mention’).
Ostrowski et. al.
The paper in question is by Ostrowski et. al. titled The Effect of Weight Training Volume on Hormonal Output and Muscular Size and Function and was published in the Journal of Strength and Conditioning Research in 1997. In it, they recruited 35 men but 8 dropped out leaving 27. This left it a bit statistically underpowered just like Brad’s study. At least they were both statistically underpowered.
The loss of 8 subjects left 9 in each group so the study was still balanced in that regard. The men had been lifting from 1-4 years and had an average 1.7 bodyweight squat but only a 1.1 bodyweight bench press. This makes their squat much higher than in Brad’s study and bench press relatively similar relative to bodyweight and their training experience was essentially identical. So that’s a wash.
Each did the same weekly workout which had a push, pull, legs and arm day with 3 exercises per muscle. They tested 1, 2 or 4 sets per exercise so it was structurally similar to Brad’s study although they used a split routine rather than full-body three times weekly.
Assuming that each set that involves a given muscle counts as one set (an issue I’ll address in a later article), the volumes ended up being 7, 14 and 28 sets for triceps (due to both the pushing day and arm day hitting triceps) but only 3, 6 and 12 sets per week for the quadriceps (due to only the one leg day). Muscle thickness was measured by Ultrasound and it’s interesting that the study explicitly stated the following

Basically, since Ultrasound is subjective, they did pilot work to ensure that he would be consistent across measurements. This is the mark of attentive scientists. Before you use a subjective measurement make sure the people doing it are consistent. If I’m doing tape measure measurements on someone, I need to show that I’m consistent day-to-day. Otherwise I can pull the tape tighter one day than another and get results that aren’t real.
So they did the pre- and post-training Ultrasound measurements (and so far as I can tell, the time point at which this was done was not mentioned which is a methodological problem that I must honestly point out) to determine the changes in muscular thickness.
For quads (rectus femoris only) they found this:

Now, the researchers state that there was no statistical difference between groups although a trend is certainly seen for the highest volume group gaining more than the other two. Likely the lack of statistical difference was due to the low number of subjects and the paper being statistically underpowered but gains in both an absolute and percentage sense more or less doubled from 3 to 12 sets.
This isn’t a shock given previous data which shows a pretty good relationship between training volume and growth up to about 10+ sets. But nor is it particularly meaningful in that 12 sets is still pretty low in the big scheme (since it wasn’t tested we can’t know if more volume would have generated more growth). We might ask why this study found growth from 12 sets per week while Brad’s need FORTY-FIVE (again, in similarly trained subjects) with NONE at lower volumes but no matter. The hand-waving explanation in the discussion was this.

Basically, our 9 set group was close to their 12 set group in terms of volume but we needed nearly 4 times as much to get growth but we dunno why. Ok.
But it’s the triceps data that is more interesting. Here is Ostrowski’s actual data. If you’re confused about why the numbers are so much lower it’s because the quad data was in millimeters squared and triceps was in millimeters.

Now, again the researcher concluded that there was no statistically significant difference in groups (probably due to it being underpowered) but there is a trend where you can see that 14-sets got double the growth as 7-sets but 28 sets got no further growth. Well, not unless you count doubling your total sets for 0.1% of growth to be significant.
Basically it shows a plateau in growth at the middle volume. 14 was better than 7 but 28 was no better than 14. Mind you we are looking at 1 vs 2 mm here but even by percentage it’s about double. Got it? In contrast to the leg data, the triceps data showed a clear plateau in growth at 14 sets/week. More volume was only better to a point.
Now, in his textbook, Brad actually reports Ostrowski’s original conclusion: that there is no significant difference in growth between groups. Here’s the chart from his book (with the author’s name misspelled).

Somehow, those previous non-significant results became significant now in the discussion of this most-recent paper, which seems awfully convenient. Brad says they re-analyzed the data statistically but, hmm, why didn’t he do that before? Just another oddity for a man “seeking the truth” who seems to have changed how a given study data was reported and analyzed but no matter. Regardless, I won’t disagree that the data shows a trend towards the moderate volume getting better growth for triceps and the lack of a difference is likely a statistical issue due to it being underpowered. It still doesn’t change the fact that 28 sets was no better than 14 sets.
There was a clear plateau in the response of hypertrophy to training volume.
But that’s just the beginning and now it’s time to pull the trigger on the smoking gun. The fact that Brad can’t address, James addressed badly and nobody but me seems to have caught (including the peer reviewers for the journal).
Here is a screenshot from the discussion in Brad’s paper.

I’m going to go in reverse and first look at the quad data. Brad reports that the lowest volume group got 6.8% increase while the highest volume group got the 13.1% shown above. It doesn’t really matter in this case but it’s a bit of an oddity that the middle data point wasn’t mentioned at all.
I mean it doesn’t change the results meaningfully but what, were they trying to save ink by not writing “…the 6 set/week group got a 5% gain and the 12 set group got….”. It seems an odd omission and is atypical for a study examining previous work. Reporting all three data points wouldn’t have changed their conclusion so why didn’t they do it?
I suspect it was to set up a pattern of data reporting for the triceps data.
Here Brad states:
Changes in triceps brachii MT in Ostrowski et al. (19) study were 2.2% for the lowest volume condition (7 sets per muscle/week) and 4.7% for the highest volume condition (28 sets per muscle/week). Similarly, our study showed changes in elbow extensor MT of 1.1% versus 5.5% for the lowest (6 sets per muscle/week) versus highest (30 sets per muscle/week) volume conditions, respectively.
Basically he reports the Ostrowski data as agreeing with his where the highest volume group (28 sets/week similar to his 30 set group) got more growth than the lowest volume group (7 sets/week). Now, in the strictest sense this is true that the 28 set group did outperform the 7 set group.
Except that it’s not actually true because the 14 set group did just as well as the 28 set group (or rather the 28 set group did no better than the 14 set group). And here is why this matters:
In omitting the middle data point, the conclusion from Ostrowski
is not only CHANGED but COMPLETELY REVERSED.
What Ostrowski found for triceps was a clear plateau in growth at 14 sets. Doubling that had no meaningful impact unless you count that extra 0.1% as meaningful. 28 sets was as good as 14 which was better than 7. Yes I am beating a dead horse. What Brad reported was that 28 sets was better than 7 which happened to match his paper’s conclusion (30 sets better than 6 sets). If this is still unclear, look at this graphic I made. The black line is what Ostrowski found, the red what Brad reported by not presenting the data for 14 sets/week

See the difference? Ostrowski found the black line, an increase from 7 to 14 sets and then a plateau at 14 sets. Brad ignored the middle data point which makes it look like it was simply more is better. If this is still unclear let me use a simple car analogy:
You come to my car lot and I have three cars that cost 70,000$, 140,000$ and 280,000$. The first goes 100 MPH, the second goes 200 MPH, the third goes 201 MPH. You tell me you want the fastest car I have for the best purchase price. I tell you that, well, this car is 70,000$ but only goes 100 MPH but this baby is 280,000$ but goes 201 and I don’t tell you about the middle car. I tell you that the more you spend the faster you go and get the contract out for you to sign.
Is what I said true? Well technically it is. The more expensive car goes faster.
Is what I said actually true or HONEST? No. Because for half as much money you’d only go 1 MPH slower and there is a plateau in performance at 140,000$. I bet if you found out about the middle car later you’d feel ripped off or lied to.
That’s what Brad did here. He ignored the middle data point that showed a plateau and which directly contradicted his conclusion. And by doing so he made a paper that actually contradicted him magically agree with him, all through the highly scientific method of “misrepresenting the data”.
James’ Weak Sauce Defenses
Now, James, god bless him, spent a lot of time trying to defend this in my Facebook group. He was playing semantic silly buggers, based on how the discussion was written (very carefully) to make it seem like it wasn’t a misrepresentation of the data. But it is. Because the way the data was presented reverses what was actually found in the Ostrowski paper. Nothing changes that fact. The data was completely mis-represented to change what it actually said.
Brad and the rest took a paper that disagreed with their conclusions and made it agree with them by ignoring data points and misrepresenting the actual data from that study. This is not science. And, flatly, if anybody writing a paper Brad disliked had done it, Brad would have anti-gurued them faster than you can drink a protein shake and the letter to the editor would have been written before he had closed the PDF on the paper he didn’t like. But just as Brad is apparently above Cochrane guildelines, it’s ok for HIM to misrepresent data.
When James couldn’t argue this anymore, he finally admitted that yes, it was a misrepresentation but that it wasn’t deliberate. Yeah, seems like an uncannily convenient mistake to make, to ignore the data point that changes the conclusion of a paper from disagreeing with you to agreeing with you when your career has supposedly been built on the quest for truth and an attention to accuracy.
It Was Deliberate
James is also wrong that it wasn’t deliberate. And I told him this and of course he told me I didn’t understand statistics again or something equally irrelevant. Ok, James.
Because, in 2016, Brad and I discussed the Ostrowski paper. He claimed it said that more volume was better and I looked and it and pointed out that the triceps data didn’t actually support that. That the 28 set group was not meaningfully superior to the 14 set group unless 0.1% better gains is meaningful for twice the training volume. That it showed a clear plateau. And thankfully I use Gmail which saved the EMAIL I SENT HIM at that time which appears below.
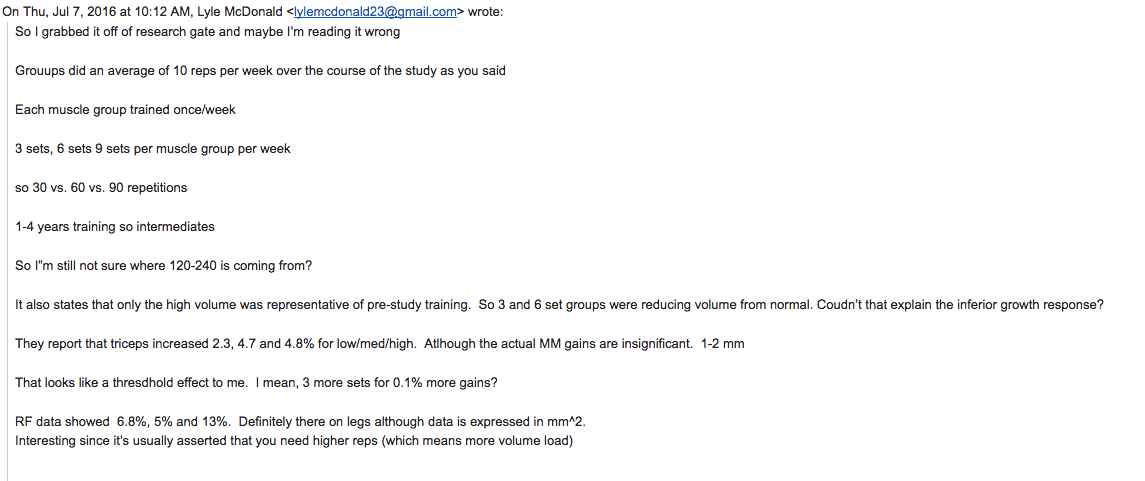
Now, I won’t share his private email response but in essence he said he’d look at it and think about it. Clearly he did and decided to just ignore the middle data point when it was convenient to change that paper’s conclusion to agree with his.
And this means James is wrong. Brad knows EXACTLY what Ostrowski found. He knows for a fact that the triceps data shows a plateau because I told him about it 2 years ago. He even wrote it in his textbook.
Brad knew exactly what he was doing here.
That makes it deliberate. James can hem and haw and deflect and obfuscate all he wants but he can’t address this or he would have. Or any of my other points. And statistics doesn’t have anything to do with it.
The Still Unanswered Issues
So let me sum up the issues I have that James, Brad and others have steadfastly failed to address:
- Ultrasound is subjective. This is inherent to the method but can be addressed by having the tech do two tests on different days to see if they get reproducible results. Or having two techs take repeat measurements for comparison purposes.
- The study wasn’t blinded, introducing, by Cochrane standards, THE standards of scientific review, a high risk of bias. No exception is made for Brad Schoenfeld or anybody else.
- Brad did the Ultrasound himself. Knowing who was in which group because it wasn’t blinded.
- Brad did the Ultrasound, for at least some subjects at a time point where edema is known to still be present (48 hours).
- Brad measured some people at 72 hours and lord knows what that changes. We don’t know who got measured when since it wasn’t (apparently) randomized.
- Brad and James have published a paper (several in fact) indicating that they believe a priori that more volume equals more growth. That is their personal bias: more volume means more growth.
- Most importantly and almost making the rest irrelevant:
Brad, or whomever was involved in writing the discussion, misrepresented data from a previous paper in such a way that the conclusions of that paper go from CONTRADICTING Brad’s results to SUPPORTING it. If it was deliberate, and I think it was, that makes it a boldfaced lie.
Brad just happened to run into the one person who had already discussed Ostrowski with him and happened to mis-reference it in the prepublication paper which made me look more closely and see what he did. It’s a shame I wasn’t on the peer review for this mess. I wouldn’t have caught the statistics but this shit would never have gotten past me.
If it wasn’t deliberate, then it represents an indefensible oversight for someone claiming to be a meticulously detail driven scientist “seeking the truth”. I mean, it’s not as if he didn’t re-read Ostrowski, re-grind the data and know that the triceps data didn’t support his paper’s conclusion.
He even said that he re-analysed the statistics and decided that they were statistically significant. He knew that the moderate volume triceps group got the same results as the higher volume group. He knew that the paper contradicted him. And his only recourse was to leave out the middle data point to make the conclusions seem opposite to what they were.
Even if you want to hand-wave #1-6 away as methodological nitpicking (note: the same type Brad himself engages in in papers he doesn’t like), #7 can’t be addressed or defended. Period. Scientists don’t get to misrepresent data when it suits them. They don’t get to ignore data when it disagrees with them.
Yet here we are and Brad did just that very thing. And, James Krieger, your statistics don’t make a damn bit of difference in that context. Not blinding the study and misrepresenting data to change a paper’s conclusion have NOTHING to do with your statistics or pretty pictures or any other deflections or obfuscations you can come up with.
NOTHING.
Ball’s in your court, James.
Addendum Saturday September 22nd, 2018: Since publishing the above piece, Brad Schoenfeld and Eric Helms (the unnamed individual above who is now being named) have both BLOCKED me on Facebook. This is the behavior of people like Gary Taubes, Dr. Fung, Tim Noakes and other gurus who will not accept criticism of their work. Draw your own conclusions. Go check it out, ask them about this paper and the problems with it and I bet they block you too.
Addendum Saturday September 22nd, 2018: While Brad and Eric have both blocked me, James Krieger has attempted to defend and deflect with the following:
“Thus, be wary when someone places too much emphasis on the results of a single study, or tends to draw conclusions with high levels of certainty based on limited data. Each study is a very small piece of a larger puzzle, a puzzle of which you may not have an idea of what it looks like until you’ve gathered enough pieces to do so. And even when you do start to get enough pieces, you still only have an idea of what the picture might finally look like. Your conclusion remains tentative. And in science, you almost never have all the pieces of the puzzle. You make an educated guess as to what the puzzle ”
That’s actually pretty funny since this is EXACTLY what their group is doing. Drawing a strong conclusion (which I quoted above) from a single paper based on shoddy methodology where data was LIED about in the discussion. But no matter, in a week or two I will be examining all of the studies on this topic, about 7 of them at last count. And we’ll see what the overall body of literature says about the topic. And unlike Schoenfeld et. al., I won’t be misrepresenting any data to do it.
Addendum Saturday September 22nd, 2018: Lucus Tafur has done his own in-depth analysis of the Schoenfeld et. al. study. Lucas makes many similar points to myself, along with several others.
Addendum Monday September 24th, 2018: Brian Bucher has written an extensive analysis of the statistics and interpretation of them which can be found on Redditt. Short version: none of the three statistical methods used in the paper support the claimed conclusions. NONE OF THE THREE.
James Loves to Obfuscate
In a similar vein, James Krieger has written yet another semi-deflecting piece, examining briefly Lucas Tufur’s piece but ignoring completely Brian’s analysis defending the paper. He makes many amusing arguments, accusing me of not having enough experience to understand how research is done (note: Layne said “You don’t even science” as well) but this is typical guru speak. Somehow I know that studies should be blinded and randomized, something Brad Schoenfeld does not. So maybe I know a bit more about proper study methodology than he thinks.
He also blathers about the cost and funding involved. I never said science was easy and I know it’s expensive. Yet Brad has published FORTY SEVEN papers this year (that’s 4 per month, most researchers do maybe 1 a year). Funding is clearly not an issue and perhaps Brad should do one GOOD study per year instead of putting his name on 4 per month.
He also babbles something about whether or not Ostrowski was blinded or why I didn’t mention it above. This is a pure deflection. Essentially he’s arguing that since other studies might be methodologically unsound, it’s ok for theirs to be. This is like arguing in court that “Yes, this man may have murdered someone. But how do we know YOU haven’t murdered someone.” to deflect attention from the issue at hand The methodology of Ostrowski is not at question here, the methodology (or lack thereof) of Brad’s paper is. Regardless, it’s irrelevant.
Mike Israetel used the same moronic argument. It’s the argument of the intellectually dishonest.
Whether or not the Ostrowski is blinded or not doesn’t matter because I’m not the one holding it up as providing evidence. If James is saying it should be dismissed for not being blinded, then Brad can’t use it in the discussion to support his conclusions. Either the data is valid or it’s not. In using it in his discussion, Brad is clearly taking the results as valid.
James can’t have it both ways.
And that is still just a deflection from the fact that, whether the Ostrowski data is good or not, BRAD LIED ABOUT WHAT IT SAID to change it’s conclusions from contradicting to agreeing with him. Of course, James has still failed to address that so far as I can tell. But neither has anybody else addressed it. Apparently Brad Schoenfeld, unlike any researcher before or after, gets to flat out lie about data in a discussion and nobody even blinks.
James also argues that the studies on edema timing aren’t relevant sine it was a new stimulus to the trainees. Well the study Brad cited in his discussion was in beginners too. And the second study I cited above was a long-term training study so the argument is wrong anyhow. James can’t allow a study of untrained individuals as support for their claim and then say a novel stimulus (i.e. untrained subjects) doesn’t apply. He can’t have it both ways, now can he? And yet this is exactly what he’s trying to do.
But James, like Eric and Brad, has gone full guru mode at this point. He has no other recourse. They are backed into a corner without a ledge to stand on and just have to keep arguing in circles. Let me be clear, I give James points for at least trying to address *some* of the points that were brought up. Neither Brad nor Eric Helms had the guts do that. Brad ignored every question and Eric defended him with pathetic deflections.
At least James tried. He just didn’t do a very good job of it.
James Krieger, Just Another Guru
Oh yeah, James Krieger has now blocked me on FB as well, right after publishing his article. But it’s always easier to win an argument when the person you’re arguing with or attacking can’t argue back isn’t it? I’d note that I left all three of them in my FB group to give them the opportunity to address criticisms and all three voluntarily left. I did not and would not have blocked or booted them so that I could win by default. They punked out by choice.
So add James Krieger to the guru group of Brad Schoenfeld and Eric Helms. Their actions are no different than endless others before them: Tim Noakes, Dr. Fung, Gary Taubes, Layne Norton. Individuals who just block and ignore criticism rather than address it. If that doesn’t tell you everything you need to know about the conclusions of this study, no amount of in-depth analysis will help.
Science is predicated on discourse and discussion of data. No real scientist avoids discussion or uses guru tactics like Brad and Eric have. Those actions are the mark of the guru and nothing more.
Addendum 2020: As I mentioned above, the entire guru circle jerk has now flip flopped. After defending Brad’s paper for over a year and a half, they’ve all basically dismissed the findings. I mean in the sense that ALL of their volume recommendations are in the 10-20 set/week range. The same conclusion I drew a year and a half ago. They knew it was bullshit then and they know it’s bullshit now. They’re just hoping nobody will notice that they’ve all basically reached the point of admitting:
Lyle McDonald was right all along.
But NONE of them have the fucking sack to admit it. Not only are they gurus, they’re gutless ball-less gurus.
You can read even more about this issue here.
Facebook Comments